8.2 Cross-Attention: One Sequence Querying Another Sequence
Author
jshn9515
Published
2026-04-09
Modified
2026-05-04
In the previous section, starting from Bahdanau attention, we saw one of the earliest important motivations behind the attention mechanism: do not force the whole input sentence into a fixed-length vector. Instead, when generating each target word, dynamically look for the most relevant information in the source sentence. This idea can be summarized in one sentence:
Whatever information is needed at the current time step, use the current state to search for that information in the input sequence.
In Bahdanau attention, the decoder hidden state is matched against all encoder hidden states, and then the encoder states are weighted and summed according to the matching degree. This process is already very close to cross-attention in modern attention mechanisms. The difference is that modern Transformers express this in a more unified and more matrix-based way: one sequence provides queries, and another sequence provides information that can be queried.
In this section, we focus on cross-attention. Self-attention will be discussed separately in the next section. This way, we can first make clear the structure where one sequence queries another sequence, and then transition to the case where a sequence queries itself.
import mathimport dnnlpyimport matplotlib.pyplot as pltimport numpy as npimport scipy.stats as statsimport torchimport torch.nn as nnfrom torch import Tensorplt.rc('figure', dpi=100)dnnlpy.set_matplotlib_format('svg')print('PyTorch version:', torch.__version__)
PyTorch version: 2.12.0+cpu
8.2.1 From Soft Alignment to Cross-Attention
In machine translation, we have two sequences:
The source-language sequence, for example an English sentence;
The target-language sequence, for example a Chinese sentence.
A traditional seq2seq model first uses an encoder to compress the source sentence into a context vector, and then the decoder relies on this vector to generate the target sentence step by step. Bahdanau attention changed this process: the decoder no longer relies only on one fixed vector. Instead, at every generation step, it revisits all hidden states of the source sentence.
In other words, every time the decoder generates a word, it asks once:
For the word I am about to generate now, which positions in the source sentence are the most important?
This is the prototype of cross-attention.
Cross-attention means that positions in one sequence attend to positions in another sequence. Its difference from self-attention is that self-attention is mutual viewing inside one sequence, while cross-attention is interaction between two sequences.
If we understand it through machine translation:
A certain position in the target sequence is responsible for asking the question;
Each position in the source sequence is responsible for providing candidate information;
The model retrieves the most useful content for the current generation step from the source sequence according to relevance.
So, cross-attention is essentially a cross-sequence information retrieval mechanism.
8.2.2 Query, Key, and Value: Three Elements of Dynamic Information Retrieval
Modern attention usually uses query, key, and value to describe this process. Although these three names may look a bit abstract, the intuition behind them is not complicated. We can think of attention as a retrieval process:
Query represents what we are currently looking for;
Key represents how each position participates in matching;
Value represents what content each position actually provides.
Intuitively, this is very similar to how we search for information online. We type what we want to find into the search box, and the search engine returns a group of candidate results. Each result usually has a title and the corresponding webpage content. We first use our current need and these titles to judge which results are more worth paying attention to, and then extract truly useful information from the concrete content of those results.
In cross-attention, query and key/value usually come from different sequences. For example, in machine translation, the hidden states output by the encoder are the key and value, while the current hidden state of the decoder is the query. The decoder uses the query to match the encoder keys, obtains a set of weights, and then takes a weighted sum of the encoder values to obtain the context information needed by the current target position.
This is actually the core idea of Bahdanau attention. It is just that modern attention writes the matching process between the current decoder state and all encoder states in a unified Q, K, V form, while separating K and V to strengthen the expressive power of the model.
Therefore, in cross-attention, a natural correspondence is:
Query comes from the sequence that is being generated or updated;
Key and value come from the sequence being queried.
That is, whoever is asking produces the query; whoever is being queried produces the key and value.
This sentence is important. Cross-attention does not require the two sequences to look at each other equally. Instead, it has a clear direction: one sequence actively queries, and the other sequence provides information that can be queried.
At this point, we have roughly become familiar with query, key, and value. But I believe there are still many questions: why split these roles apart? In particular, why should key and value, which come from the same queried sequence, still be separated? We will discuss this question in detail in the next subsection.
8.2.3 Why Split Them into Query, Key, and Value?
In the previous subsection, we treated Q, K, and V as three roles in attention: query represents the current need, key is used for matching, and value is used to provide content. This way of saying it is convenient for understanding, but it also leads to several natural questions:
Why should the input be split into query, key, and value?
Since key and value usually come from the same sequence in cross-attention, why should key and value still be separated?
Can I add another one myself, for example Q, K, V, W?
Let us first look at the first question: why do we need Q, K, and V?
This question is relatively easy to explain. In fact, if we do not split things into Q, K, and V, the same vector has to simultaneously take on several roles: what I want to find, whether I am worth being matched, and what content I should provide if attended to. This returns to the fixed context vector problem we discussed earlier: it has to take on multiple different functions at the same time, so the model’s expressive ability is limited. After splitting into Q, K, and V, the model can learn the query need, matching features, and transferable content from different angles, and thereby learn by itself how to organize information.
Next, look at the second question: why should key and value be separated?
An intuitive answer is: the information used for matching and the information finally retrieved do not have to be the same kind of information.
In a search engine, we may first look at the title, keywords, or abstract to judge whether a webpage is relevant; but the information we really need may be hidden in the body of the webpage. The title is suitable for matching, while the body is suitable for providing content. The two are related, but they are not exactly the same.
An important design in attention is to separate two things:
First thing: who is most relevant to me now?
Second thing: if I attend to it, what information can it provide?
This is like looking for a book in a library. We have a need in mind, which is a bit like the query. We use the book title, table of contents, tags, or abstract to judge which book is relevant, and these clues are a bit like the key. What we actually read and absorb is the concrete content in the book, which is a bit like the value.
If key and value are completely tied together, the model can only use the same representation for both matching and content transmission. If key and value are separated, the model can use one representation to decide who is more relevant, and use another representation to decide what the relevant position should contribute. In other words:
If we change the key, we change which positions in the source sequence the model attends to;
If we change the value, while keeping the attention weights unchanged, we change the content retrieved by the model.
So, attention weights are determined by query and key, but the final output also depends on value. After separating key and value, the model can decouple the matching space and the content space, allowing them to learn different functions separately.
For the third question: can I add another one myself, for example Q, K, V, W?
In theory, of course you can. We can certainly design a more complex attention mechanism, add more roles, for example let W represent some auxiliary information, or introduce more matching dimensions. But Q, K, and V have already been proven to be a very effective design. They divide the core functions of attention into three roles, with enough expressive power while not being too complicated. Adding more roles may make the model harder to train, or require more data to learn the division of labor among these roles.
However, it should be noted that many concrete designs in attention are not necessarily derived from some theory. The explanations we give now are post-hoc explanations. More accurately, they are a set of design choices that have been proven effective in practice and are convenient for training and implementation. Precisely because of this, for questions like why not Q, K, V, W, or whether the scoring function can use other similarity measures, there is often no standard answer. Different designs usually make trade-offs among expressive power, computational efficiency, training stability, and implementation complexity. This is also why there are many variants of attention.
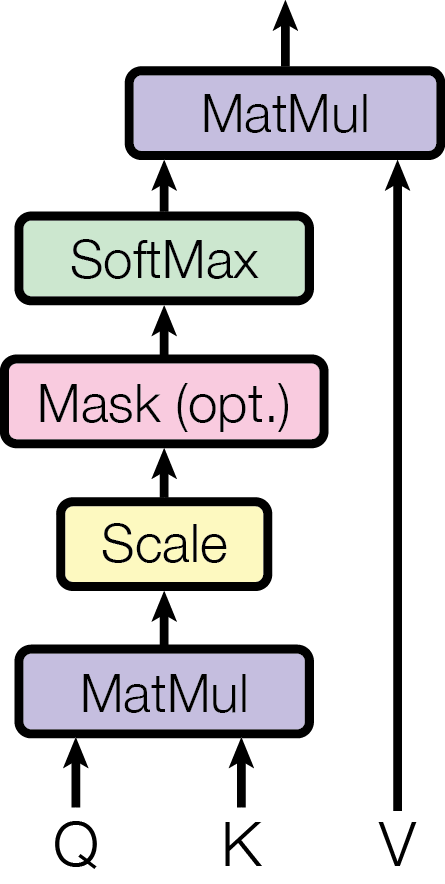
8.2.5 Matrix Form of Cross-Attention
Now we write cross-attention in matrix form.
Suppose there are two sequences:
The query sequence is represented as \(X \in \mathbb{R}^{n_x \times d}\);
The queried sequence is represented as \(Y \in \mathbb{R}^{n_y \times d}\).
Here, \(n_x\) is the length of the query sequence, \(n_y\) is the length of the queried sequence, and \(d\) is the hidden dimension.
Cross-attention first obtains the following through linear projections:
\[
Q = X W_Q, \quad K = Y W_K, \quad V = Y W_V
\]
Then it computes the similarity between query and key:
\[
S = QK^\top
\]
Here, \(S \in \mathbb{R}^{n_x \times n_y}\). Its \(i\)-th row and \(j\)-th column represent the relevance score from the \(i\)-th position in the query sequence to the \(j\)-th position in the queried sequence.
Next, apply softmax to each row to turn the scores into weights:
\[
P = \operatorname{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)
\]
Finally, use these weights to take a weighted sum of value:
\[
O = PV
\]
Putting them together gives the scaled dot-product attention that we are very familiar with:
In cross-attention, the most important point is that Q comes from one sequence, while K and V come from another sequence. This is also why it is called cross-attention. It is widely applicable to machine translation, image-text matching, question answering, and other tasks that require cross-sequence interaction.
In the code below, we implement a minimal version of cross-attention using random tensors. Here x and y are two different sequences. Q comes from x, and K and V come from y.
Note
Here we need to clarify that our implementation mainly aligns with PyTorch’s nn.MultiheadAttention, rather than implementing the most general possible dimensional design for attention.
In nn.MultiheadAttention, embed_dim simultaneously represents the input dimension of the query, the total projected dimension of query/key/value, and the final output dimension of attention. It only additionally provides kdim and vdim, which allow the original input dimensions of key/value to differ from the query.
From the attention mechanism itself, however, the dimensions can be more flexible. The input dimensions of query, key, and value can be different; the matching dimension of query/key and the content dimension of value can also be different; and the final output dimension does not necessarily have to equal embed_dim. As long as query and key can correctly compute attention scores, and the attention weights can align with value for the weighted sum, the attention computation is valid.
class CrossAttention(nn.Module):def__init__(self, embed_dim: int):super().__init__()self.embed_dim = embed_dimself.q_proj = nn.Linear(embed_dim, embed_dim)self.k_proj = nn.Linear(embed_dim, embed_dim)self.v_proj = nn.Linear(embed_dim, embed_dim)self.out_proj = nn.Linear(embed_dim, embed_dim)def forward(self, query: Tensor, key: Tensor, value: Tensor, need_weights: bool=False, ) ->tuple[Tensor, Tensor |None]:# Make sure the sequence lengths of key and value matchif key.size(-2) != value.size(-2):raiseAssertionError('`key` and `value` must have the same sequence length.' ) q =self.q_proj(query) k =self.k_proj(key) v =self.v_proj(value) scores = q @ k.transpose(-2, -1) scores = scores / math.sqrt(self.embed_dim) attn_weights = scores.softmax(dim=-1) attn_output = attn_weights @ v output =self.out_proj(attn_output)if need_weights:return output, attn_weightsreturn output, None
Let us test the input and output shapes of this cross-attention:
We can see that the shape of attention weights is (batch size, query length, key/value length). That is, each position in the query sequence assigns a set of weights to all positions in the queried sequence.
The \(i\)-th row and \(j\)-th column in the figure represent how much the \(i\)-th position in the query sequence attends to the \(j\)-th position in the queried sequence. The darker the color, the larger the weight, meaning that the query position pays more attention to the information from the queried position. Since this is cross-attention, the horizontal axis and vertical axis correspond to two different sequences.
However, there is still a small-looking but actually very important detail here: when computing scores, we do not directly write Q @ K.T; instead, we divide the dot-product result by \(\sqrt{d_k}\). This detail may look inconspicuous, but it has a very important effect on the training stability of the model. So why is this done?
8.2.6 Why Divide by \(\sqrt{d_k}\)?
In Transformers, the most common form is the scaled dot-product attention we just discussed:
Its difference from the most original attention is that it divides the scores by \(\sqrt{d_k}\).
Why do this? Because when the feature dimension \(d_k\) becomes larger, the numerical values of the dot products also tend to become larger. If these larger scores are directly sent into softmax, softmax can easily become extremely sharp, meaning that the probability of one position becomes close to 1, while the probabilities of the other positions are almost close to 0. As a result, gradients may become smaller, and training may become unstable. So, dividing by \(\sqrt{d_k}\) is essentially controlling the scale of the scores, keeping softmax in a more suitable working range.
We can use the code below to look at this phenomenon more intuitively. We randomly generate query and key, and compare the entropy of the attention distribution before and after scaling under different dimensions. The lower the entropy, the sharper the distribution.
You can see that without scaling, as \(d_k\) increases, softmax becomes sharper and the entropy drops more obviously. After scaling, the distribution becomes much more stable. This is an important reason why scaled dot-product attention became the standard setup.
8.2.7 How One Target Position Queries the Entire Source Sequence
To understand cross-attention more concretely, let us look at only one position in the target sequence.
Suppose the decoder is now going to generate the \(i\)-th word in the target sentence. At this time, it has a hidden representation \(x_i\), and this representation is projected into a query:
\[
q_i = x_i W_Q
\]
The encoder output at each position in the source sentence is projected into key and value:
\[
k_j = h_j W_K, \quad v_j = h_j W_V
\]
Here, \(h_j\) is the encoder representation of the \(j\)-th position in the source sentence.
Then, the current query computes relevance with all keys:
\[
s_{ij} = q_i \cdot k_j
\]
After these scores pass through softmax, we obtain the attention weights:
Finally, the model takes a weighted sum over all values:
\[
o_i = \sum_j \alpha_{ij} v_j
\]
This output \(o_i\) is the context information that target position \(i\) retrieves from the source sequence.
From this perspective, cross-attention does not compress the source sentence into one vector. Instead, it generates a dynamic context for every position in the target sequence. Different target positions can attend to different parts of the source sentence, so it is naturally suitable for modeling translation, image-text matching, question answering, and other tasks that require cross-sequence interaction.
8.2.8 The Position of Cross-Attention in the Transformer
In the classic Transformer structure for machine translation, the model is divided into two parts: encoder and decoder.
The encoder is responsible for processing the source sequence. Inside it, self-attention is mainly used so that each position in the source sequence can integrate contextual information within the source sentence.
The decoder is responsible for generating the target sequence. It usually contains three types of submodules:
Masked Self-Attention: lets the already generated positions inside the target sequence interact with each other, while avoiding looking at future words;
Cross-Attention: lets the target sequence query the source sequence representations output by the encoder;
Feed-Forward Network: further applies nonlinear transformations to the representation at each position.
Among them, cross-attention is the information bridge between the encoder and the decoder.
Without cross-attention, the decoder can only rely on its own historical generation results, and it is difficult for it to know what the source sentence specifically says. After adding cross-attention, at every generation step, the decoder can revisit the encoder output and choose the most relevant source-sentence information according to the current generation state. This continues the core idea of Bahdanau attention: generation does not rely only on a fixed context, but dynamically searches the input sequence at every step.
The difference is that the Transformer fully matrixizes this process. It no longer relies on recurrent neural networks to pass hidden states step by step. Instead, through Q, K, V and matrix multiplication, it turns cross-sequence information interaction into a module that can be computed efficiently in parallel.
Of course, although cross-attention is easiest to understand through machine translation, its applications are far beyond translation. As long as a task has a structure where one sequence needs to retrieve information from another sequence, cross-attention can be used. For example:
In image captioning, the text decoder can query image features;
In visual question answering, the question representation can query image-region features;
In text question answering, the question can query document content;
In multimodal models, text tokens can query image patches, and image patches can also query text tokens.
These tasks look different on the surface, but they can all be abstracted into the same process:
The current sequence proposes a need, another sequence provides candidate information, and attention completes dynamic retrieval according to relevance.
Therefore, cross-attention is an important mechanism for Transformers to connect different information sources. It allows the model not only to process relationships inside one sequence, but also to model relationships between different sequences, different modalities, and different information sources.
8.2.9 Summary
In this section, we moved from the soft-alignment idea of Bahdanau attention to modern cross-attention.
Conceptually, cross-attention continues the key motivation of Bahdanau attention: do not compress all input information into a fixed vector; instead, let the model dynamically access relevant information when needed. In implementation, modern Transformers use Q, K, V and matrix multiplication to write this dynamic access as a unified, efficient, and parallelizable computation module.
At the same time, we should also remember that Q, K, and V are not the only structure derived from some perfect theory. They are a very successful engineering design. They split “asking a query”, “participating in matching”, and “providing content” into several learnable roles, allowing the model to learn by itself during training how to organize information. Understanding this division of labor is enough. We do not need to explain every design as some kind of necessity.
However, up to now, what we have discussed is still interaction between two sequences. Next, a more natural question is: if there is no other sequence, and only one sequence itself, can it also use the same method to let different internal positions query each other?
This is the topic of the next section: self-attention.