8.3 Self-Attention: Internal Information Interaction Within a Sequence
Author
jshn9515
Published
2026-04-09
Modified
2026-05-04
In the previous section, we have already viewed cross-attention as an information retrieval mechanism across sequences: one sequence is responsible for proposing the query, and another sequence is responsible for providing the key and value. In this way, a certain position in the target sequence can retrieve relevant information from the source sequence according to the current need.
In this section, we discuss self-attention. It still uses the scaled dot-product attention introduced in the previous section, so we will not fully derive the formula again. What we really need to focus on is: when query, key, and value no longer come from two different sequences, but all come from the same sequence, how does the meaning of attention change?
Simply speaking, cross-attention solves how one sequence queries another sequence, while self-attention solves how one sequence queries itself. This looks like only the input source has changed, but the impact it brings is very large: every token in the sequence can directly interact with other tokens, and thus update its own representation according to the context.
This is also one of the key reasons why Transformer can process sequence information without using RNN.
import mathimport dnnlpyimport matplotlib.pyplot as pltimport numpy as npimport torchimport torch.nn as nnfrom torch import Tensorplt.rc('figure', dpi=100)dnnlpy.set_matplotlib_format('svg')print('PyTorch version:', torch.__version__)
PyTorch version: 2.12.0+cpu
8.3.1 From Cross-Attention to Self-Attention
First recall the structure of cross-attention. Suppose there are two sequences: the query sequence \(X\) and the sequence being queried \(Y\). In cross-attention, query comes from \(X\), and key and value come from \(Y\):
\[
Q = XW_Q, \quad K = YW_K, \quad V = YW_V.
\]
That is, every position in \(X\) will query all positions in \(Y\). Bahdanau attention in machine translation is a typical example: the decoder queries all outputs of the encoder according to the current state, which is to retrieve the most useful information from the source sentence for the current generation.
The form of self-attention and cross-attention is very similar. The only difference is that \(Q\), \(K\), and \(V\) are all obtained from the same input sequence \(X\):
\[
Q = XW_Q, \quad K = XW_K, \quad V = XW_V.
\]
This is the core formal difference between self-attention and cross-attention. Its problem is no longer which positions in the source sentence the target word should look at, but which tokens in the same sentence a token should refer to when understanding itself.
For example, consider the following sentence:
The animal did not cross the street because it was tired.
When the model processes it, looking at this word alone provides almost not enough information. Does it refer to animal, or street? This judgment must depend on the context. The model needs to combine the relationships among words such as animal, street, and tired to update the representation of it more reasonably. What self-attention does is let the position of it directly look at other positions in the whole sentence, and then aggregate information according to relevance. In this way, it is no longer an isolated pronoun, but a representation fused with context.
So, simply speaking, self-attention moves the dynamic retrieval idea of cross-attention into the sequence itself: every token is asking, in order to update myself, from which positions in this sequence should I retrieve information?
8.3.2 How Each Token Obtains Context
The most important role of self-attention is to generate its own contextual representation for each token.
Ordinary word embeddings are usually more like relatively fixed word-meaning representations. For example, the word bank, no matter what sentence it appears in, may initially correspond to the same embedding vector. But in real language, the meaning of bank changes with the context:
1. I deposited money in the bank.
2. I sat by the river bank.
The bank in the first sentence is closer to a financial bank, and the bank in the second sentence is closer to a river bank. If the model only looks at bank itself, it is hard to distinguish these two meanings. It must combine surrounding words such as money, deposited, and river to judge how this word should be understood in the current context.
Self-attention is exactly doing this. For each position in the sequence, it uses its own query to match the keys of all positions in the whole sequence, and then aggregates the corresponding values according to the obtained weights. The previous section has already discussed the full attention formula. Here we only emphasize its meaning in self-attention:
The query of the current token represents what contextual information I currently need;
The keys of all tokens represent how I can be matched;
The values of all tokens represent what content I can provide if I am attended to.
After weighted aggregation, the output representation will contain both the information of the current token itself and the information it retrieves from the context.
From this perspective, the output of self-attention is not the independent representation of each token, but the contextual representation of each token in the current sequence. This is also why it can become the core module of Transformer.
8.3.3 PyTorch Implementation of Self-Attention
Since the previous section has already discussed scaled dot-product attention, here we directly look at self-attention from the implementation perspective. In code, self-attention is very similar to cross-attention. The real difference is only one thing: the Q of cross-attention comes from one sequence, while K and V come from another sequence; the Q, K, and V of self-attention all come from the same input x.
Below is a minimal version of self-attention. Here we do not consider multi-head attention or mask first, and only keep the core computation process.
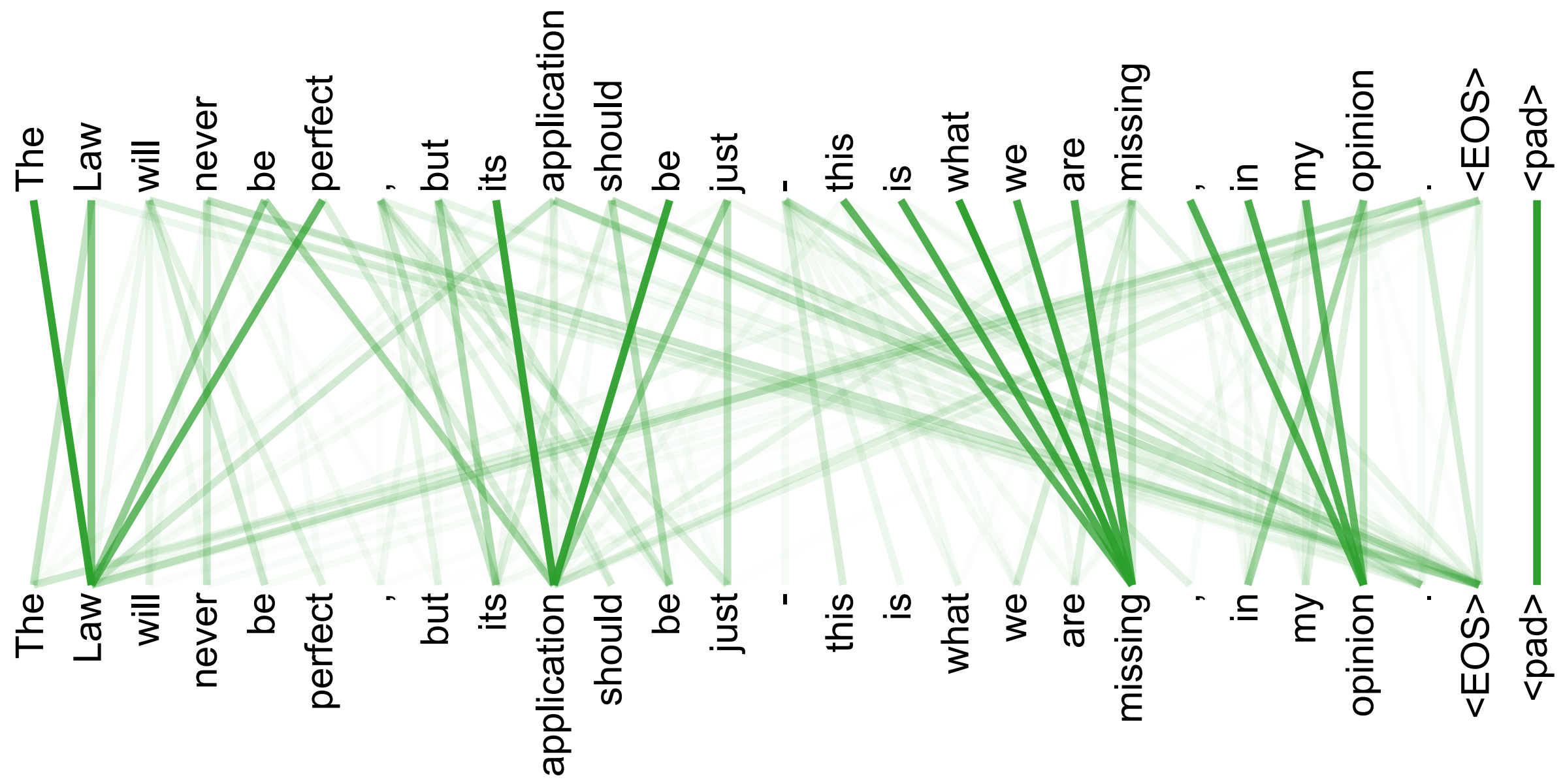
The thing most worth noticing here is the shape of attention weights. For a sequence with length 5, the attention weight matrix is \(5 \times 5\). Its \(i\)-th row represents the weights assigned by the \(i\)-th token to all tokens in the whole sequence when updating itself. For self-attention, the weight matrix is always a square matrix, and both the number of rows and columns are equal to the sequence length.
Another point worth noticing is that self-attention does not output only one vector. Instead, it outputs a new representation for every position in the sequence. The input size and output size are both (batch_size, seq_len, d_model). The sequence length does not change. What changes is the representation of each position. The vector of each token has been rewritten by the context and fused with information from other positions.
8.3.4 Self-Attention Is a Dynamic Information Graph
Besides contextual representation, there is another very useful perspective for understanding self-attention: we can view it as constructing a dynamic information graph inside the sequence.
In this graph, every token is a node. Self-attention lets every node build connections with all other nodes, and the strength of the connection is determined by the attention weight. For a sequence with length \(n\), the attention weight matrix is an \(n \times n\) matrix, which can be viewed as the weighted adjacency matrix of this graph.
This perspective is clearly different from RNN and CNN.
The information flow of RNN is more like a chain. If the information of the first token wants to influence a token far later, it usually needs to be passed step by step along the hidden states. The information flow of CNN is more like a local window. Each layer can only let neighboring positions interact, and if we want to build long-distance connections, we need to stack multiple convolution layers.
Self-attention is more like a complete graph. In theory, every position can directly access all other positions in one layer. No matter how far apart two words are, the information path length between them is 1.
More importantly, this graph is not fixed. It is dynamically computed according to the current input. The same token may attend to different positions in different sentences. For example, bank may pay more attention to money and deposited in a financial context, and may pay more attention to river and sat in a natural-environment context. This shows that what self-attention builds is not a static graph, but an input-dependent dynamic information graph.
This viewpoint can help us understand why self-attention is flexible: it does not use a fixed structure to process all sequences, but lets the model decide by itself, according to each input sample, which positions should exchange more information.
Of course, we can visualize the attention map to help us observe which positions the model pays more attention to in a certain layer and a certain attention head. But it should be noted that attention map weights are not equal to a full model explanation. They are only one part of the weighted aggregation of value information. The final output will also be jointly influenced by multi-head attention, residual connections, feed-forward networks, layer normalization, and multi-layer stacking. Attention map can be used as a window for understanding model behavior, but we cannot simply say that a high weight must mean the model made the judgment because of this word. We will discuss the interpretability of attention maps separately later.
8.3.5 Why Self-Attention Is Suitable for Sequence Modeling
At this point, we can see more clearly why self-attention is suitable for sequence modeling.
First, it can directly build long-distance dependencies. In RNN, if the 1st token wants to influence the 100th token, the information needs to pass through many time steps. Although LSTM and GRU alleviate this problem through gating mechanisms, the path is still relatively long. In self-attention, the 1st token and the 100th token can directly interact in the same layer, so the information path is shorter.
Second, it is easier to parallelize. The \(t\)-th hidden state of RNN depends on the \(t-1\)-th hidden state, so it is hard to fully parallelize during training. Self-attention first generates Q, K, and V for all tokens at the same time, and then computes the relationships among all positions at once through matrix multiplication. This process is very suitable for large-scale parallel computation on GPUs.
Finally, it is not limited to a local window. CNN is successful in image tasks because local structures are very important. But in language, some relationships may span very far positions. CNN needs to gradually expand the receptive field through multi-layer stacking, while self-attention allows any two positions to interact from the beginning.
We can roughly compare the three types of structures:
Table 1: Comparison of RNN, CNN, and Self-Attention
Structure
Information interaction method
Long-distance dependency
Parallelism
CNN
Gradually expands the receptive field through local windows layer by layer
Requires stacking multiple layers
Good
RNN
Passes information step by step along time steps
The path is relatively long
Poor
Self-Attention
Any two positions directly interact
The path is very short
Good
This does not mean that self-attention is absolutely better than RNN or CNN in all aspects, because different structures have different inductive biases. RNN is naturally suitable for processing sequences in temporal order, CNN naturally emphasizes local patterns, while self-attention emphasizes global interaction and dynamic information aggregation more. The success of Transformer largely comes from this combined advantage of self-attention: it can let all positions directly exchange information, and can also write the computation as matrix operations suitable for hardware acceleration.
8.3.6 Limitations of Self-Attention
Although self-attention is strong, it is not perfect by itself. Understanding its limitations actually makes it easier to understand why Transformer still needs other components later.
The first limitation is that it has no natural sense of order by itself. Attention mainly assigns weights according to the matching degree between vectors. If we do not give the model any positional information, then it cannot naturally distinguish the first word from the fifth word.
For example:
1. dog bites man
2. man bites dog
These two sentences contain exactly the same words, but their meanings are completely different. If the model only knows what words there are, but does not know the order of these words, it is hard to correctly understand the sentence. Therefore, Transformer usually needs to add positional encoding or positional embedding, so that the model knows where each token is located in the sequence.
The second limitation is computation and memory cost. For a sequence with length \(n\), self-attention needs to compute an \(n \times n\) attention matrix. In other words, the longer the sequence is, the faster the computation and memory usage of attention grow. This is usually still acceptable for ordinary-length sentences, but for long documents, high-resolution images, videos, or multimodal inputs, the \(n^2\) cost becomes very obvious. Many efficient attention methods later, such as linear attention, sparse attention, sliding-window attention, and flash attention that we will discuss separately later, are essentially trying to alleviate this problem.
The third limitation is that the expressive ability of a single attention head is limited. One self-attention operation only computes relevance in one group of query, key, and value projection spaces. However, the relationships between a token and other tokens may have many types: some relationships are more syntactic, some are more semantic, some are related to position, and some are related to coreference. If only one attention head is used, the model may have difficulty capturing these different types of relationships at the same time. Therefore, Transformer usually does not use only a single self-attention, but uses multi-head attention (MHA). Multi-head attention lets the model perform attention in multiple subspaces in parallel, and each head has the opportunity to focus on different types of information.
These three limitations also remind us: although self-attention provides the core mechanism for information interaction inside a sequence, it still needs to work together with other designs to form a complete Transformer. Positional encoding supplements order information, efficient attention methods try to reduce long-sequence cost, and multi-head attention lets the model observe the sequence from more than one perspective.
8.3.7 Summary
In this section, we applied the attention mechanism introduced in the previous section to the inside of the same sequence. Different from cross-attention, the query, key, and value in self-attention all come from the same input sequence. Therefore, each token is no longer only representing itself in isolation, but can update its own representation according to the whole context.
From this perspective, the core role of self-attention is not simply computing a weighted sum, but establishing a dynamic information interaction mechanism inside the sequence. Each token can decide, according to the current input, from which positions it should obtain information and how much information it should obtain. Precisely because of this global interaction, self-attention can model long-distance dependencies more directly than RNN, and can make distant positions connect more easily than ordinary CNN.
However, self-attention itself still has limitations. It has no natural sense of order and needs positional encoding to supplement positional information. It needs to compute an \(n \times n\) attention matrix, so the computation and memory cost is large under long sequences. Meanwhile, a single attention head can only observe the sequence in one projection space, so its expressive ability is also limited. In the next section, we will continue along the last point and introduce multi-head attention, and see how the model understands the same sequence from multiple different perspectives at the same time.