10.1 为什么 Attention 是 IO-Bound
在前面的章节里,我们已经知道了 self-attention 的基本计算过程。给定 \(Q, K, V\),Attention 的计算(忽略缩放)通常写成:
\[ S = QK^\top, \quad P = \text{softmax}(S), \quad O = PV \]
从这个公式上看,Attention 好像没什么特别的,本质上就是两次矩阵乘法,中间夹了一个 softmax。既然矩阵乘法是 GPU 最擅长的操作,那么一个很自然的直觉就是:Attention 应该主要受算力限制。也就是说,GPU 的浮点计算能力有多强,Attention 就应该跑得有多快。
但真实情况恰恰不是这样。
实际上,标准 Attention 往往不是 compute-bound,而是 IO-bound。换句话说,它慢并不是因为“算不过来”,而是因为“搬不过来”。GPU 并没有把时间花在乘法和加法上,而是花在了把数据从显存搬到片上缓存,再从片上缓存搬回显存这件事上。
这个结论第一次听起来会有点反直觉。毕竟 \(QK^\top\) 和 \(PV\) 都是大矩阵乘法,为什么瓶颈不在算,而在数据访问?
答案就藏在 Attention 的注意力矩阵 \(S\) 和概率矩阵 \(P\) 里。它们的大小是 \(N \times N\),如果序列长度是 \(N\),那么这两个矩阵的规模就会随着 \(N^2\) 增长。这两个中间结果太大,通常不可能长期留在片上 SRAM 里,只能频繁写回 HBM,再从 HBM 读出来继续参与后续计算。真正拖慢 Attention 的,就是这一来一回的大规模数据搬运。
那么,为什么从硬件执行的角度看,Attention 天然是一个 IO 很重的算子?
要回答这个问题,我们就要从一个更底层的视角出发,拆解 Attention 在硬件上的真实执行过程,看看它到底把时间花在了哪里。
10.1.1 先建立一个硬件视角:算子到底会被什么限制?
在分析 Attention 之前,我们先思考一个最基本的问题:一个 GPU 算子为什么会慢?
从硬件角度看,通常只有两种可能:
- 算例不够:浮点运算太多,GPU 的计算单元先被打满。
- 带宽不够:数据搬运太多,显存带宽先被打满。
如果一个算子的瓶颈在计算,我们称它是 compute-bound;如果瓶颈在内存访问,我们称它是 memory-bound 或 IO-bound。这里的 IO,不是指磁盘读写,而是指更广义的数据搬运。对于 GPU 而言,最重要的一类 IO 就是 SRAM 和 HBM 之间的数据搬运。
所以,当我们说一个算子是 IO-bound,本质上是在说它花了太多时间在搬数据上,而不是算数据上。
10.1.1.1 算术强度:判断性能瓶颈的核心指标
那我们怎么判断一个算子更像 compute-bound,还是更像 IO-bound?
在高性能计算领域,有一个非常核心的指标,那就是 算数强度(Arithmetic Intensity):
\[ \text{Arithmetic Intensity} = \frac{\text{FLOPs}}{\text{Bytes Moved}} \]
也就是说,每搬运 1 字节数据,能够做多少次浮点运算。这个指标直接决定了算子更接近 compute-bound 还是 IO-bound。
从直觉上可以这样理解:
- 如果一个算子读一点数据,就反复计算很多次,那么它的算术强度高,就更可能是 compute-bound;
- 如果一个算子读一点数据,只算几下就丢掉了,那么它的算术强度低,就更可能是 IO-bound。
所以,判断一个算子性能瓶颈时,一个非常重要的问题就是:我们读进来的数据,到底被重复利用了多少次?
10.1.1.2 矩阵乘法:一个 compute-bound 的经典例子
举个简单的例子,矩阵乘法为什么通常是 compute-bound?
假设我们有这样一个矩阵乘法:
\[ C = AB \]
其中, \(A\) 是 \(M \times K\) 的矩阵,\(B\) 是 \(K \times N\) 的矩阵,结果 \(C\) 是 \(M \times N\) 的矩阵。
矩阵乘法虽然计算量很大,但它有一个非常好的性质:输入元素会被反复复用。例如,矩阵 \(A\) 的每个元素会被用来计算 \(C\) 中的一整行,而矩阵 \(B\) 的每个元素会被用来计算 \(C\) 中的一整列。假设矩阵 \(A\) 和 \(B\) 的大小都是 \(N \times N\),那么每个元素被复用的次数大约是 \(N\) 次。因此,矩阵乘法的算术强度大约是 \(O(N)\),也就通常是 compute-bound。
这也是为什么 GPU 对 GEMM(通用矩阵乘法)极其擅长。不是因为矩阵乘法天生简单,而是因为它非常适合做分块、缓存和数据复用。
10.1.1.3 GPU 内存不是一块平地,而是分层的
理解 Attention 的 IO 问题,还需要知道 GPU 的存储并不是统一的。从速度和容量上看,GPU 的内存是分层的,大致可以粗略理解为:
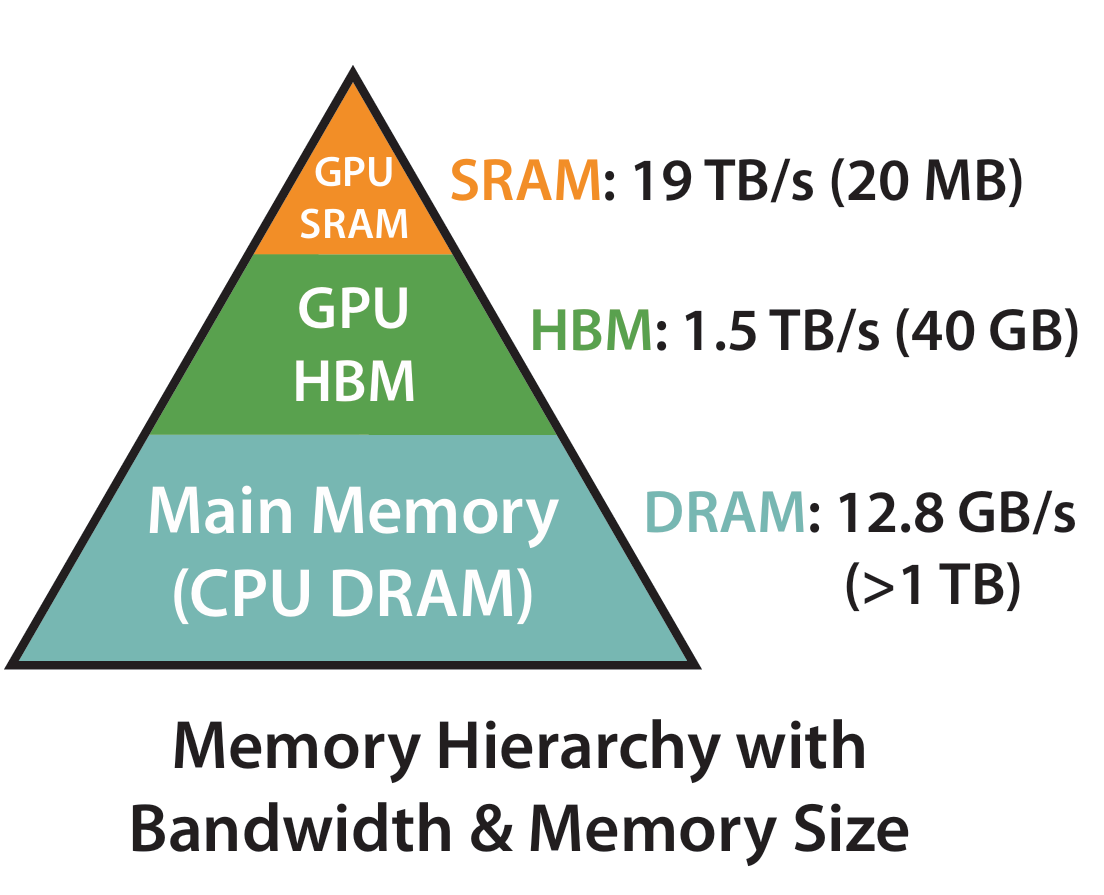
- 寄存器(Register):容量极小,但最快,访问延迟几乎为零
- SRAM / Shared Memory / L2 Cache:容量小,但速度快,访问延迟低,速度约为 19 TB/s
- HBM(High Bandwidth Memory):容量大,但访问延迟高,速度约为 1.5 TB/s
所以,对一个高性能算子来说,一个核心原则就是:尽量把数据留在片上,减少对 HBM 的访问。因为 HBM 虽然也很快,但和片上 SRAM、寄存器相比,仍然慢得多。更重要的是,HBM 带宽是整个 GPU 上很多线程块共享的稀缺资源。一旦某个算子需要频繁把大张量写回 HBM,再重新读回来,它就很容易被带宽卡住。
同时,我们还要考虑一个点,那就是 GPU 的算力增长速度远远快于显存带宽的增长速度。这种现象被称为 内存墙(Memory Wall)。也就是说,尽管现代 GPU 的 FLOPs 数字非常惊人,但显存带宽的提升是相对缓慢的。如果一个算子不能有效地复用数据,而是频繁地从 HBM 里读写大块张量,那么即使算术本身不复杂,也很可能成为性能瓶颈。
接下来,我们就把这个视角真正用到 Attention 上。
10.1.2 标准 Attention 到底把时间花在哪里了?
我们先只看最基本的单头 Attention,忽略 batch 维度,也先不考虑缩放因子。计算过程是:
\[ S = QK^\top, \quad P = \text{softmax}(S), \quad O = PV \]
其中,\(Q, K, V \in \mathbb{R}^{N\times d}\),\(S, P \in \mathbb{R}^{N\times N}\),\(O \in \mathbb{R}^{N\times d}\);\(N\) 是序列长度,\(d\) 是特征维度。
现在我们分别看两件事:
- 需要做多少计算?
- 需要搬多少数据?
10.1.2.1 先看 FLOPs:Attention 的计算量并不小
- 第一步,计算 \(QK^\top\)。这是一个 \((N\times d)\cdot(d\times N)\) 的矩阵乘法,输出是 \(N\times N\)。它的 FLOPs 量级大约是 \(2N^2d\),这里的 2 来自乘加操作,通常按 2 次 FLOPs 计。
- 第二步,计算 softmax。对 \(S\) 的每一行做 softmax,需要做减最大值、指数、求和、归一化等操作。每个元素大约需要计算一个指数和一次除法,所以 FLOPs 量级大约是 \(2N^2\)。
- 第三步,计算 \(PV\)。这是一个 \((N\times N)\cdot(N\times d)\) 的矩阵乘法,FLOPs 量级也是 \(2N^2d\)。
因此,标准 Attention 的总 FLOPs 大约是:
\[ \text{FLOPs} \approx 2N^2d + 2N^2 + 2N^2d = 4N^2d + 2N^2 \approx O(N^2d) \]
所以,从计算量上看,Attention 确实不便宜。问题在于:计算量大,不代表一定是 compute-bound。还得看这些计算是建立在怎样的数据访问模式上的。
10.1.2.2 再看 IO:真正麻烦的是 \(N\times N\) 的中间矩阵
我们把标准 Attention 的执行过程写得更准确一些:

假设我们使用 float32,每个元素占 4 字节。我们做一个很粗略的估算,只抓主导项。
- 读取 \(Q, K, V\):每个都是 \(N\times d\) 的矩阵,所以总共需要读入 \(12Nd\) 字节。
- 读取和写回一次 \(S\):\(S\) 是 \(N\times N\) 的矩阵,读写一次需要 \(8N^2\) 字节。
- 读取和写回一次 \(P\):\(P\) 也是 \(N\times N\) 的矩阵,读写一次需要 \(8N^2\) 字节。
- 写回输出 \(O\):\(O\) 是 \(N\times d\) 的矩阵,写回需要 \(4Nd\) 字节。
因此,总 IO 量大致是:
\[ \text{IO} \approx 12Nd + 8N^2 + 8N^2 + 4Nd = 16N^2 + 16Nd \approx O(N^2 + Nd) \]
当 \(N \gg d\) 时,IO 量级主要由 \(N^2\) 项主导。这说明,Attention 最重的 IO 开销,不是输入输出本身,而是对两个 \(N\times N\) 中间矩阵的反复读写。
10.1.2.3 算术强度:长序列并不会让 Attention 更 compute-bound
现在我们把 FLOPs 和 IO 放在一起。前面估算过,标准 Attention 的 FLOPs 大约是 \(O(N^2d)\),IO 大约是 \(O(N^2 + Nd)\)。因此,Attention 的算术强度大约是:
\[ \text{Arithmetic Intensity} = \frac{O(N^2d)}{O(N^2 + Nd)} = O\left(\frac{d}{1 + \frac{d}{N}}\right) \]
当序列长度足够大时,可以近似为 \(O(d)\)。这说明,Attention 的算术强度在大序列长度时主要由特征维度 \(d\) 决定,而与序列长度 \(N\) 的关系不大。
这是一个非常关键的点。
很多算子随着问题规模变大,数据复用也会变得更充分,因此更接近 compute-bound。但标准 Attention 不是这样。即使你把序列拉长,它的计算量变大了,但 IO 也变大了,算术强度并没有明显提升。相反,在很多情况下,长序列只会让 IO 问题变得更严重。
10.1.2.4 为什么这件事特别糟糕?
因为这两个中间矩阵太大了。如果 \(N=4096\),那么一个 \(4096\times 4096\) 的矩阵就有 16M 个元素,按照 float32 来算就是 64MB。也就是说,光一个 \(S\) 就已经是几十 MB。再加上 \(P\),再考虑多头、batch、反向传播中更多的中间状态,显存压力会非常夸张。这也就是为什么长序列会放大 Attention 的 IO 问题。
这不只是“占地方”这么简单。更重要的是,这些大矩阵还要被反复搬运。它们太大,不可能一直留在片上 SRAM 中,所以每次后续操作都不得不重新从 HBM 读回来。这就让 Attention 呈现出一个很不理想的模式:
- 大量中间结果被显式写回;
- 这些中间结果很快又要被重新读出来;
- 但它们的复用方式并没有像 GEMM 那样被很好地局部化在片上。
所以,从硬件角度看,这就是一个很典型的 IO 压力很大的算子。
10.1.3 本章小结
这一章里,我们并没有改变 Attention 的数学形式,而是换了一个角度,从 GPU 执行和数据移动的视角重新看了一遍 Attention。
我们得到了三个关键结论:
- 标准 Attention 虽然包含两次大矩阵乘法,但它的瓶颈往往不在算力,而在 IO。
- 问题的根源在于它会显式构造并保存两个 \(N\times N\) 的中间矩阵:注意力分数 \(S\) 和 softmax 后的概率矩阵 \(P\)。这些矩阵很大,导致需要反复读写 HBM。
- 随着序列长度增加,\(N^2\) 级别的中间状态和 IO 会迅速膨胀,因此长序列会把这个问题进一步放大。
而一旦我们真正理解了这一点,一个问题就出现了:既然最贵的是中间矩阵的读写,那我们能不能不把它们完整存下来?
这正是 FlashAttention 的出发点。下一节我们就会看到,它并不是去近似 Attention,而是通过更好的分块和更好的 IO 组织方式,让 Attention 的执行过程尽可能少地访问 HBM。