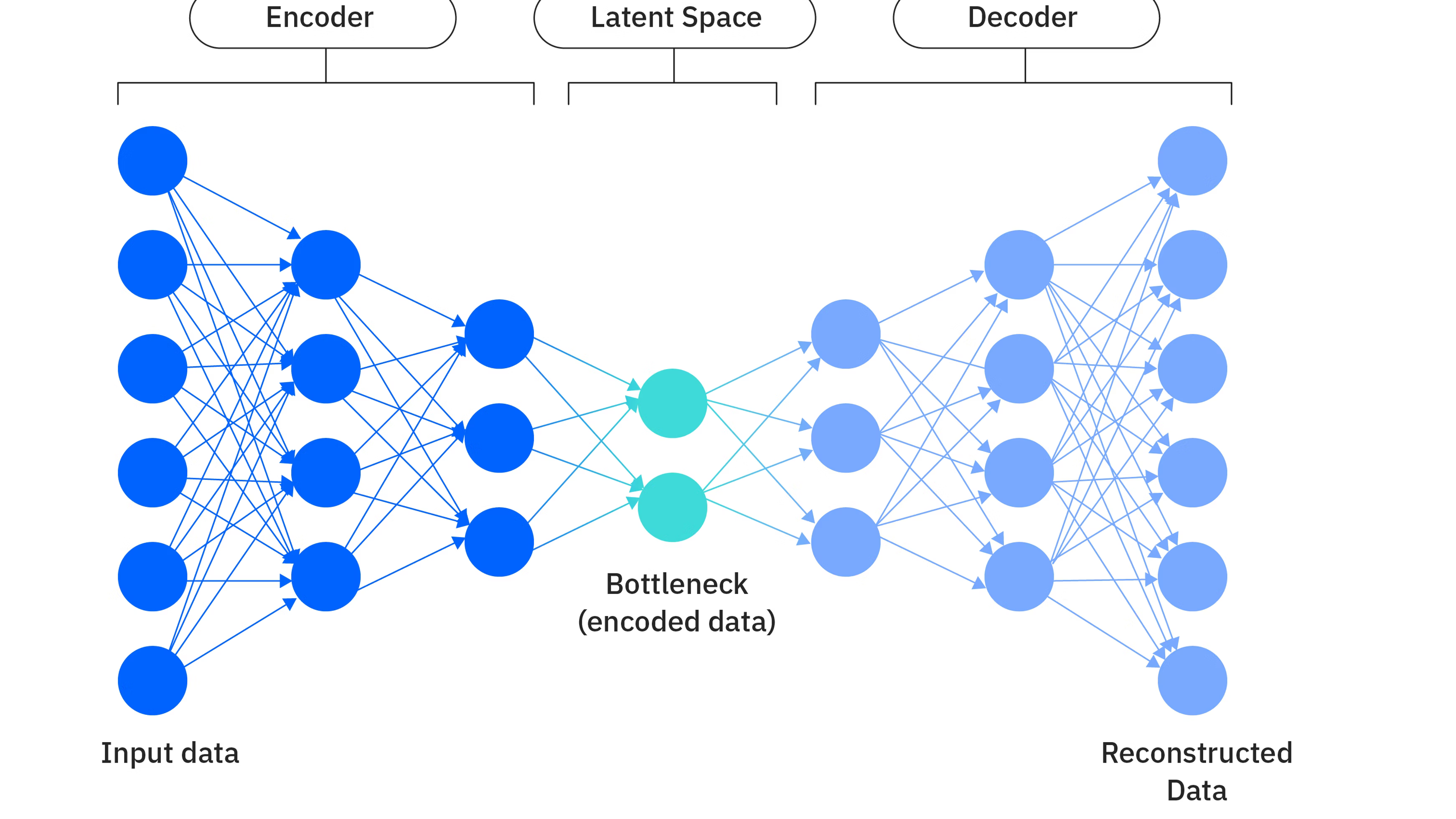
上一节我们介绍了 AutoEncoder。它通过 encoder 把输入压缩到 latent space,再通过 decoder 把 latent representation 重建回原始数据。这样的结构很优雅,也很直观。
但普通 AutoEncoder 有一个根本问题:
它学到的 latent space 往往是不规整的,因此很难直接用于生成。
也就是说,虽然每个训练样本都能被编码成一个点 \(z\),decoder 也能从这个点重建出原图,但这些点在潜空间里可能分布得很零散、很碎片化。模型只需要保证这些点能够被正确解码,却不关心整个潜空间是否连续、平滑,也不关心不同样本之间的区域是否具有良好的结构。这就带来一个直接后果:如果我们随便从潜空间里采样一个点,再送进 decoder,得到的结果往往并不像真实数据。换句话说,普通 AutoEncoder 更像是在做压缩与重建,而不是在做真正意义上的生成建模。
而 VAE 的想法是引入一个潜变量 \(z\)。这个 \(z\) 不再是一个点,而是一个概率分布。它用来表示那些看不见、但真正决定数据如何生成的潜在因素。比如一张人脸图像 \(x\),表面上看只是由大量像素组成,但在这些像素背后,真正影响它的因素可能是姿态、光照、表情、发型,甚至人物身份本身的特征。这些因素通常没有被显式标注出来,但它们确实在控制这张图像是如何形成的。
因此,我们希望用一个潜变量 \(z\) 来捕捉这些潜在因素。这样一来,数据 \(x\) 就不再被看成是凭空出现的,而是先由某个潜在状态 \(z\) 决定,再由 \(z\) 生成最终观测到的数据 \(x\)。
这就是 Variational Autoencoder (VAE) (Kingma and Welling 2022) 的核心思想。与其直接在高维数据空间中建模,不如先假设数据背后存在一个更低维、更有结构的潜在空间,并让模型学习这个潜在空间的概率分布,以及从这个空间生成数据的方式。
import math
from typing import Literal
import dnnlpy.nn as dnn
import dnnlpy.nn.functional as dF
import torch
import torch.nn as nn
from torch import Tensor
type LossFn = Literal['mse', 'bce']
print('PyTorch version:', torch.__version__)
PyTorch version: 2.12.1+cpu
13.2.1 从确定性编码到概率编码
在普通 AutoEncoder 中,一个输入 \(x\) 会被 encoder 映射到一个确定的向量:
\[
z = f_\theta(x)
\]
也就是说,一个样本对应 latent space 中的一个点。
VAE 则不一样。它不再把一个样本编码成一个确定的点,而是编码成一个概率分布:
\[
q_\phi(z \mid x)
\]
通常我们会把这个分布设为高斯分布:
\[
q_\phi(z \mid x) = \mathcal{N}(z; \mu(x), \sigma^2(x))
\]
VAE 的 encoder 不再直接输出一个 latent vector,而是输出两个量:
- 均值 \(\mu(x)\)
- 方差 \(\sigma^2(x)\)(实践中常输出 \(\log \sigma^2(x)\),以避免数值不稳定)
于是,一个样本 \(x\) 不再对应潜空间中的单个点,而是对应潜空间中的一小片概率区域。
以下是 VAE 的网络结构示意图:
所以,普通 AutoEncoder 的潜空间是每张图片对应一个精确坐标;而 VAE 想做的是,让这些坐标点的周围都带有一定的概率密度,让每张图片对应一个小云团。同时,这些云团之间要尽量连接、平滑,并整体贴近一个简单的先验分布(通常是标准正态)。这样一来,潜空间就不再是零碎的,而变得更连续、更适合采样。
13.2.2 VAE 想建模什么
从生成模型的角度看,我们真正关心的是数据是怎么生成出来的。以下是 VAE 的流程:
先从一个简单的先验分布中采样 latent variable:
\[
z \sim p(z)
\]
通常取标准正态分布:
\[
p(z) = \mathcal{N}(0, I)
\]
再根据 \(z\) 生成数据 \(x\):
\[
x \sim p_\theta(x \mid z)
\]
这里 \(p_\theta(x \mid z)\) 由 decoder 参数化。
所以,VAE 背后的建模思想就是,观测数据 \(x\) 不是直接产生的,而是由某个隐藏变量 \(z\) 通过一个生成过程产生的。
把这两步相乘,整个联合分布就可以写成:
\[
p_\theta(x, z) = p(z)\, p_\theta(x \mid z)
\]
但问题是,在训练的时候,我们只能看到 \(x\),看不到 \(z\)。所以,我们需要把 \(z\) 积分掉,得到边缘分布:
\[
p_\theta(x) = \int p_\theta(x, z)\, dz = \int p(z)\, p_\theta(x \mid z)\, dz
\]
其中,\(p(z)\) 规定 latent space 的整体形状,\(p_\theta(x \mid z)\) 描述如何从 latent variable 生成观测数据。
如果这个模型学得好,那么生成新样本时就很简单。首先从 \(p(z)=\mathcal{N}(0, I)\) 里采样一个 \(z\),然后用 decoder 生成一个 \(x\)。这才是真正意义上的“生成”。
所以,我们的训练目标就是,让模型学到的 \(p_\theta(x)\) 尽可能接近真实数据分布 \(p_{\text{data}}(x)\)。而对两个分布之间“接近”的衡量标准,就是最小化 KL 散度:
\[
\min_\theta D_{\text{KL}}(p_{\text{data}}(x) \parallel p_\theta(x))
\]
我们把 KL 散度展开一下:
\[
\begin{aligned}
D_{\text{KL}}(p_{\text{data}}(x) \parallel p_\theta(x)) &= \mathbb{E}_{x \sim p_{\text{data}}} \left[\log \frac{p_{\text{data}}(x)}{p_\theta(x)}\right] \\
&= \mathbb{E}_{x \sim p_{\text{data}}} [\log p_{\text{data}}(x)] - \mathbb{E}_{x \sim p_{\text{data}}} [\log p_\theta(x)] \\
\end{aligned}
\]
对于第一项,它是一个常数,因为 \(p_{\text{data}}\) 是固定的,不受 \(\theta\) 影响;而第二项是我们可以优化的。所以,最小化 KL 散度等价于最大化第二项:
\[
\max_\theta \mathbb{E}_{x \sim p_{\text{data}}} [\log p_\theta(x)]
\]
但是,现实里我们并不知道真实分布的解析式,所以只能用样本平均去近似期望:
\[
\mathbb{E}_{x \sim p_{\text{data}}} [\log p_\theta(x)] \approx
\frac{1}{N}\sum_{i=1}^{N} \log p_\theta(x^{(i)})
\]
所以,VAE 的优化目标就是最大化数据的边缘似然:
\[
\max_\theta \sum_{i=1}^{N} \log p_\theta(x^{(i)})
\]
到这里你可能会想:既然目标是让模型拟合 \(p_\theta(x)\),那直接最大化它不就行了吗?
理论上确实如此。我们想最大化:
\[
\log p_\theta(x)
\]
但问题在于,
\[
p_\theta(x) = \int p(z)\, p_\theta(x \mid z)\, dz
\]
这个积分通常是很难直接计算的,尤其当 decoder 是神经网络时,几乎不可能解析求解。更麻烦的是,如果我们想知道给定一个样本 \(x\),它最可能来自哪些 latent variable,那就需要后验分布:
\[
p_\theta(z \mid x)
\]
根据贝叶斯公式:
\[
p_\theta(z \mid x) = \frac{p(z)p_\theta(x \mid z)}{p_\theta(x)}
\]
但分母里又出现了那个难算的 \(p_\theta(x)\)。所以这个后验通常也很难精确求解。
这就是 VAE 面临的核心困难:我们想做概率生成建模,但真实后验 \(p_\theta(z \mid x)\) 很难直接算。那怎么办呢?
13.2.3 变分推断:用一个可学习分布逼近后验
VAE 的解决方法非常巧妙:既然真实后验难算,那就另外引入一个容易计算的分布去近似它。
这个近似分布记作:
\[
q_\phi(z \mid x)
\]
它由 encoder 网络给出,\(\phi\) 是 encoder 的参数。
于是,VAE 其实同时学两件事:
- Encoder 学习一个近似后验 \(q_\phi(z \mid x)\),用来推断 latent variable 的分布;
- Decoder 学习一个生成模型 \(p_\theta(x \mid z)\),用来从 latent variable 生成数据。
这就形成了一个对称结构:
\[
x \xrightarrow{\text{encoder}} q_\phi(z \mid x) \quad\text{and}
\quad z \xrightarrow{\text{decoder}} p_\theta(x \mid z)
\]
看起来和普通 AutoEncoder 很像,但普通 AutoEncoder 的 encoder 输出一个点,而 VAE 的 encoder 输出一个分布。而这一步,就是从表示学习走向概率生成建模的关键。
到这里你可能又要问了,凭什么这个 \(q_\phi(z \mid x)\) 就能逼近真实后验 \(p_\theta(z \mid x)\) 呢?我们又该如何训练它呢?
实际上,对于 \(\log p_\theta(x)\),我们有一个恒等式:
\[
\log p_\theta(x) = \mathbb{E}_{q_\phi(z \mid x)}[\log p_\theta(x \mid z)] -
D_{\mathrm{KL}}(q_\phi(z \mid x)\,\|\,p(z)) +
D_{\mathrm{KL}}(q_\phi(z \mid x)\,\|\,p_\theta(z \mid x))
\]
完整的推导将会在下一节展开。这里我们先从直觉上理解这个式子。
第一部分:重建要尽量好
我们希望从潜变量 \(z\) 中尽可能把输入 \(x\) 还原出来。也就是说,经过 encoder 得到的 \(z\),应该保留足够多的与原始输入有关的信息,这样 decoder 才能够根据 \(z\) 重建出一个与 \(x\) 尽量接近的结果。
这对应上式中的第一项:
\[
\mathbb{E}_{q_\phi(z\mid x)}\left[\log p_\theta(x\mid z)\right]
\]
这一项通常称为重建项。对于由编码器给出的潜变量分布 \(q_\phi(z\mid x)\),我们从中采样得到 \(z\),然后让解码器根据 \(z\) 去重建输入 \(x\)。如果重建得越准确,那么 \(p_\theta(x\mid z)\) 就越大,对应的 \(\log p_\theta(x\mid z)\) 也就越大,因此这一项的值也会越大。
第二部分:潜空间要尽量规整
我们还希望 encoder 输出的分布 \(q_\phi(z \mid x)\) 不要太随意,而要尽量接近先验分布 \(p(z)=\mathcal{N}(0,I)\)。
这对应上式中的第二项:
\[
D_{\mathrm{KL}}(q_\phi(z \mid x)\,\|\,p(z))
\]
这一项通常称为规整项。它的作用是,不让每个样本在潜空间里随便占一块孤岛,而是鼓励所有样本的编码分布整体靠近标准正态。这样,整个 latent space 就会变得更平滑、更连续、更可采样。
第三部分:逼近真实后验
上式中的第三项:
\[
D_{\mathrm{KL}}(q_\phi(z \mid x)\,\|\,p_\theta(z \mid x))
\]
它衡量了我们引入的近似后验 \(q_\phi(z \mid x)\) 和真实后验 \(p_\theta(z \mid x)\) 之间的差距。我们希望这个差距尽可能小,这样 \(q_\phi(z \mid x)\) 就能更好地逼近真实后验。当然,我们无法直接优化这个项,因为 \(p_\theta(z \mid x)\) 是未知的,但我们可以通过优化前两项来间接逼近真实后验。而与真实后验的误差就体现在这个 KL 散度项里。
所以,VAE 的核心思想可以概括成一句话:
VAE 的目标是最大化数据的边缘似然,同时通过引入一个近似后验来逼近真实后验,并通过 KL 散度项来规整潜空间。
13.2.4 重参数化技巧:把随机性挪到外面
解决完 VAE 的目标函数以后,我们就可以开始训练了。我们知道,在普通 AutoEncoder 中,\(z = f_\theta(x)\) 是一个确定值。但在 VAE 中,我们有:
\[
z \sim q_\phi(z \mid x)
\]
也就是说,我们不再像 AE 那样,把 encoder 输出的 latent vector 直接送进 decoder,而是把 encoder 输出的分布当成一个概率模型,从中 采样 一个 \(z\),再把这个 \(z\) 送进 decoder。
例如,如果 encoder 输出的是 \(\mu(x)\) 和 \(\sigma(x)\),也就对应以下正态分布:
\[
z \sim \mathcal{N}(\mu(x), \sigma^2(x))
\]
那么我们就想从这个正态分布中采样。
但是,这就产生了一个大问题:
采样操作本身不可导。
而神经网络训练依赖反向传播。如果中间有一个随机抽样步骤,梯度就很难从 decoder 反传回 encoder,自然也就无法训练。那么,这回我们该怎么办呢?
还记得我们希望潜空间整体接近标准正态分布吗?当 encoder 输出的是一个高斯分布时,我们可以利用一个非常关键的技巧:重参数化(Reparameterization)。
也就是说,VAE 并没有直接从 \(\mathcal{N}(\mu, \sigma^2)\) 里硬采样,而是把采样改写成:
\[
\epsilon \sim \mathcal{N}(0, I)
\]
\[
z = \mu + \sigma \odot \epsilon
\]
它的思想非常简单:
- 随机性来自一个与参数无关的噪声 \(\epsilon\)
- \(\mu\) 和 \(\sigma\) 由 encoder 网络输出
- \(z\) 是 \(\mu,\sigma,\epsilon\) 的一个确定性函数
于是,原来不可导的采样就变成了可导的变换。经过变换以后,\(\epsilon\) 可以直接随机采样,而 \(\mu\) 和 \(\sigma\) 仍然处在计算图中,损失函数可以顺利对 encoder 参数求梯度。也就是说,我们并不是直接让网络输出一个随机变量,而是让网络输出如何把标准噪声变换成目标分布。
13.2.5 VAE 的 PyTorch 实现
下面给一个最小的 VAE 编码部分示意代码,重点看重参数化这一段。
class VAE(nn.Module):
"""A fully connected variational autoencoder for small image tensors."""
def __init__(
self,
input_shape: tuple[int, int, int],
hidden_dim: int = 256,
latent_dim: int = 32,
):
"""Initialize encoder, latent heads, and decoder."""
super().__init__()
input_dim = math.prod(input_shape)
self.encoder = nn.Sequential(
dnn.Flatten(),
dnn.Linear(input_dim, hidden_dim),
dnn.ReLU(),
)
self.fc_mu = dnn.Linear(hidden_dim, latent_dim)
self.fc_logvar = dnn.Linear(hidden_dim, latent_dim)
self.decoder = nn.Sequential(
dnn.Linear(latent_dim, hidden_dim),
dnn.ReLU(),
dnn.Linear(hidden_dim, input_dim),
dnn.Sigmoid(),
dnn.Unflatten(1, input_shape),
)
def encode(self, x: Tensor) -> tuple[Tensor, Tensor]:
"""Encode inputs into latent mean and log-variance tensors."""
h = self.encoder(x)
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
def reparameterize(self, mu: Tensor, logvar: Tensor) -> Tensor:
"""Sample latent vectors with the reparameterization trick."""
std = (0.5 * logvar).exp()
eps = torch.randn_like(std)
latent = torch.addcmul(mu, std, eps)
return latent
def decode(self, z: Tensor) -> Tensor:
"""Decode latent vectors back to input-shaped tensors."""
x_hat = self.decoder(z)
return x_hat
def forward(self, x: Tensor) -> tuple[Tensor, Tensor, Tensor]:
"""Reconstruct inputs and return reconstruction, mean, and log-variance."""
mu, logvar = self.encode(x)
latent = self.reparameterize(mu, logvar)
x_hat = self.decode(latent)
return x_hat, mu, logvar
@staticmethod
def loss(
x_hat: Tensor,
x: Tensor,
mu: Tensor,
logvar: Tensor,
loss_fn: LossFn = 'bce',
beta: float = 1.0,
normalize: bool = True,
) -> tuple[Tensor, Tensor, Tensor]:
"""Compute VAE total, reconstruction, and KL losses per batch item."""
if loss_fn == 'mse':
recon_loss = dF.mse_loss(x_hat, x, reduction='sum')
elif loss_fn == 'bce':
recon_loss = dF.bce_loss(x_hat, x, reduction='sum')
else:
raise NotImplementedError(f'Unsupported loss function: {loss_fn}.')
kl_loss = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
loss = recon_loss + beta * kl_loss
if normalize:
B = x.size(0)
return loss / B, recon_loss / B, kl_loss / B
return loss, recon_loss, kl_loss
我们来测试一下:
vae = VAE(input_shape=(1, 28, 28), hidden_dim=256, latent_dim=32)
x = torch.randn(16, 1, 28, 28)
with torch.inference_mode():
x_hat, mu, logvar = vae(x)
print('x_hat.shape:', x_hat.shape)
print('mu.shape:', mu.shape)
print('logvar.shape:', logvar.shape)
x_hat.shape: torch.Size([16, 1, 28, 28])
mu.shape: torch.Size([16, 32])
logvar.shape: torch.Size([16, 32])
这里有几个关键点:
- Encoder 最后不只输出一个 latent vector,而是输出
mu 和 logvar;
reparameterize() 函数中实现了 \(z = \mu + \sigma \odot \epsilon\)。
对于 std = (0.5 * logvar).exp() 这一行,我们有:
\[
\log \sigma^2 = \text{logvar} \quad \Rightarrow \quad \sigma =
\exp\left(\frac{1}{2}\log \sigma^2\right)
\]
这一写法在实践中很常见,因为直接预测方差容易出现数值不稳定,而预测 log-variance 更方便。
13.2.6 本章小结
所以,VAE 相比普通 AE,真正多出来的不是结构稍微复杂一点,而是建模思路发生了变化。
普通 AE 的思路是:
而 VAE 的思路是:
- 假设数据由 latent variable 生成
- 用先验 \(p(z)\) 约束 latent space
- 用近似后验 \(q_\phi(z|x)\) 来推断隐藏变量
- 用 decoder 建模生成过程 \(p_\theta(x|z)\)
它本质上是一个概率生成模型,而不只是一个重建模型。如果用一句话总结,AutoEncoder 学的是如何压缩并恢复数据,而 VAE 学的是数据是如何从潜变量中生成出来的。
到这里,我们已经了解了 VAE 的基本思路。但是,我们还有一个最核心的问题没有正式回答:
VAE 的损失函数到底是怎么来的?为什么会有那个恒等式?
这就需要引入下一节的内容:变分下界(ELBO)。