import math
import torch
print('PyTorch version:', torch.__version__)PyTorch version: 2.11.0+xpu在 10.1 里,我们已经知道,标准 Attention 的真正瓶颈并不在算力,而在 IO。它之所以慢,不是因为两次矩阵乘法本身太难,而是因为中间的两个大矩阵 \(S\) 和 \(P\) 都需要显式写回 HBM,再在后续阶段重新读出来参与计算。对于长序列来说,这两个 \(N\times N\) 的中间矩阵会带来巨大的带宽压力。
既然问题出在这里,一个很自然的想法就是:能不能不要把 \(S\) 和 \(P\) 存到 HBM?
FlashAttention-1 (Dao et al. 2022) 的出发点正是这个问题。它并没有改变 Attention 的数学结果,也不是用一个近似算法去替代标准 Attention,而是换了一种更适合 GPU 的执行方式:把“算分数、做 softmax、乘 \(V\)”这几步融合在一起,在片上按块完成,只把最终输出 \(O\) 写回 HBM。
如果用一句话概括 FlashAttention-1 的核心思想,那就是:
不去存储整个注意力矩阵,而是边扫描、边归一化、边累积输出。
但这里马上会有一个新的困难。按道理来说,我们需要知道一整行以后,才能计算 softmax。如果我们只拿到一小块分数,怎么知道这一块对应的 softmax 权重是多少?又怎么保证最终结果和一次性计算整行 softmax 完全一致?
这正是 FlashAttention-1 的关键。它利用了 online softmax 的思想,使得我们即使按块扫描分数矩阵,也仍然可以正确、稳定地维护 softmax 所需的归一化统计量,最后得到与标准 Attention 完全相同的输出。
import math
import torch
print('PyTorch version:', torch.__version__)PyTorch version: 2.11.0+xpu我们先回到最普通的单头 Attention。忽略 batch 维度和 head 维度,也先省略缩放因子,计算过程写成:
\[ S = QK^\top, \quad P = \mathrm{softmax}(S), \quad O = PV \]
它们的形状分别是:
\[ Q, K, V \in \mathbb{R}^{N \times d}, \quad S, P \in \mathbb{R}^{N \times N}, \quad O \in \mathbb{R}^{N \times d} \]
对第 \(i\) 个 query,对应的输出向量可以写成:
\[ O_i = \sum_{j=1}^N P_{ij} V_j, \quad P_{ij} = \frac{\exp(S_{ij})}{\sum_{k=1}^N \exp(S_{ik})} \]
为了数值稳定,softmax 通常不会直接按上式计算,而是会先减去这一行的最大值。也就是说,我们实际使用的是:
\[ P_{ij} = \frac{\exp(S_{ij} - m_i)}{\sum_{k=1}^N \exp(S_{ik} - m_i)}, \quad m_i = \max_j S_{ij} \]
这样写的好处是,指数里的数不会太大,从而避免数值溢出。
但是,这里也恰好暴露了 softmax 的一个麻烦的地方:要算某一行的 softmax,似乎必须先知道这一整行的最大值 \(m_i\),以及这一整行的归一化分母:
\[ l_i = \sum_{k=1}^N \exp(S_{ik} - m_i) \]
这就意味着,softmax 看起来不像矩阵乘法那样容易分块。矩阵乘法可以一块一块累加,因为加法本身就是天然可结合的;但 softmax 的归一化分母依赖整行,而整行最大值又可能在扫描过程中不断变化。
也就是说,如果我们只是把 \(QK^\top\) 按块算出来,还不能立刻像 GEMM 那样简单累加,因为:
这就是标准 Attention 难以直接做“边算边归一化”的根源。
但换个角度想,我们真正需要保存的到底是什么?
对于某一行 softmax 来说,如果我们只关心最终输出 \(O_i\),其实不一定非要存下整行 \(P_i\) 和整行 \(S_i\)。我们真正需要维护的,可能只是一些更小的统计量。比如,当前看到的最大值,当前累积的指数和,以及当前累积的输出向量。如果这些量能在扫描过程中被正确更新,那么我们就不需要存储整张注意力矩阵了。
这就是 online softmax 的核心想法。在按块扫描一行分数的时候,动态维护 softmax 所需的统计量,并且随着最大值变化不断做重标定。
为了说明这件事,我们先从一行 softmax 的角度来看。
假设我们不是一次性看到整行分数,而是把这一行拆成两部分。前一部分的最大值和归一化和分别是:
\[ m^{(1)} = \max_{j \in \text{block 1}} s_j, \quad l^{(1)} = \sum_{j \in \text{block 1}} \exp(s_j - m^{(1)}) \]
后一部分的最大值和归一化和分别是:
\[ m^{(2)} = \max_{j \in \text{block 2}} s_j, \quad l^{(2)} = \sum_{j \in \text{block 2}} \exp(s_j - m^{(2)}) \]
那么,把两部分合起来以后,整行的最大值应该是:
\[ m = \max(m^{(1)}, m^{(2)}) \]
问题在于,前一部分的 \(l^{(1)}\) 是在 \(m^{(1)}\) 的标尺下计算的,而后一部分的 \(l^{(2)}\) 是在 \(m^{(2)}\) 的标尺下计算的。要把它们加起来,必须把它们搬到同一个标尺上。
于是有:
\[ l = e^{m^{(1)} - m} l^{(1)} + e^{m^{(2)} - m} l^{(2)} \]
这就是 online softmax 里最关键的一步:每当当前最大值发生变化,之前累计的量都要按照新的最大值重新缩放。
同样的道理,不只是 softmax 的分母要缩放,输出向量的累积也要缩放。
因为 Attention 的输出本质上是一个加权和:
\[ O_i = \sum_j P_{ij} V_j \]
如果我们把某个块里未归一化的权重记为
\[ \tilde{P}_{ij} = \exp(S_{ij} - \tilde{m}_{ij}) \]
那么这个块贡献的“未归一化输出”就是
\[ \tilde{O}_i = \tilde{P}_{ij} V_j \]
但它同样是建立在局部最大值 \(\tilde{m}_{ij}\) 的标尺上的,所以也必须在合并时做重标定。
现在我们把这个思路放回 FlashAttention-1 的分块场景里。
设 \(Q\) 被按行切成若干块,每块大小为 \(B_r \times d\);\(K\) 和 \(V\) 被按列切成若干块,每块大小为 \(B_c \times d\)。对于 第 \(i\) 个 query 块和第 \(j\) 个 key/value 块,我们先计算局部分数:
\[ S_{ij} = Q_i K_j^\top \]
然后在这个小块内部,计算每一行的局部最大值:
\[ \tilde{m}_{ij} = \mathrm{rowmax}(S_{ij}) \]
以及对应的局部指数和:
\[ P_{ij} = \exp(S_{ij} - \tilde{m}_{ij}), \quad \tilde{l}_{ij} = \mathrm{rowsum}(P_{ij}) \]
假设在处理这个块之前,我们已经维护了当前 query 块的三个量:
那么处理完新块后,新的最大值应为:
\[ m_i' = \max(m_i, \tilde{m}_{ij}) \]
为了把旧统计量和新统计量放到同一个标尺上,我们定义两个缩放因子:
\[ \alpha = \exp(m_i - m_i'), \quad \beta = \exp(\tilde{m}_{ij} - m_i') \]
于是,新的归一化和可以更新为:
\[ l_i' = \alpha l_i + \beta \tilde{l}_{ij} \]
而新的输出累积可以更新为:
\[ O_i' = \frac{\alpha l_i O_i + \beta P_{ij} V_j}{l_i'} \]
这条公式第一次看会有点绕,但它背后的逻辑其实很简单:
所以,FlashAttention-1 真正维护的并不是整块 \(S\) 或 \(P\),而只是:
这些量(除了 \(O\))的规模远小于 \(N\times N\) 的注意力矩阵,因此完全可以保留在片上,从而避免把中间矩阵写回 HBM。
有了 online softmax 以后,FlashAttention-1 的前向传播流程就很自然了。
整体思路是:
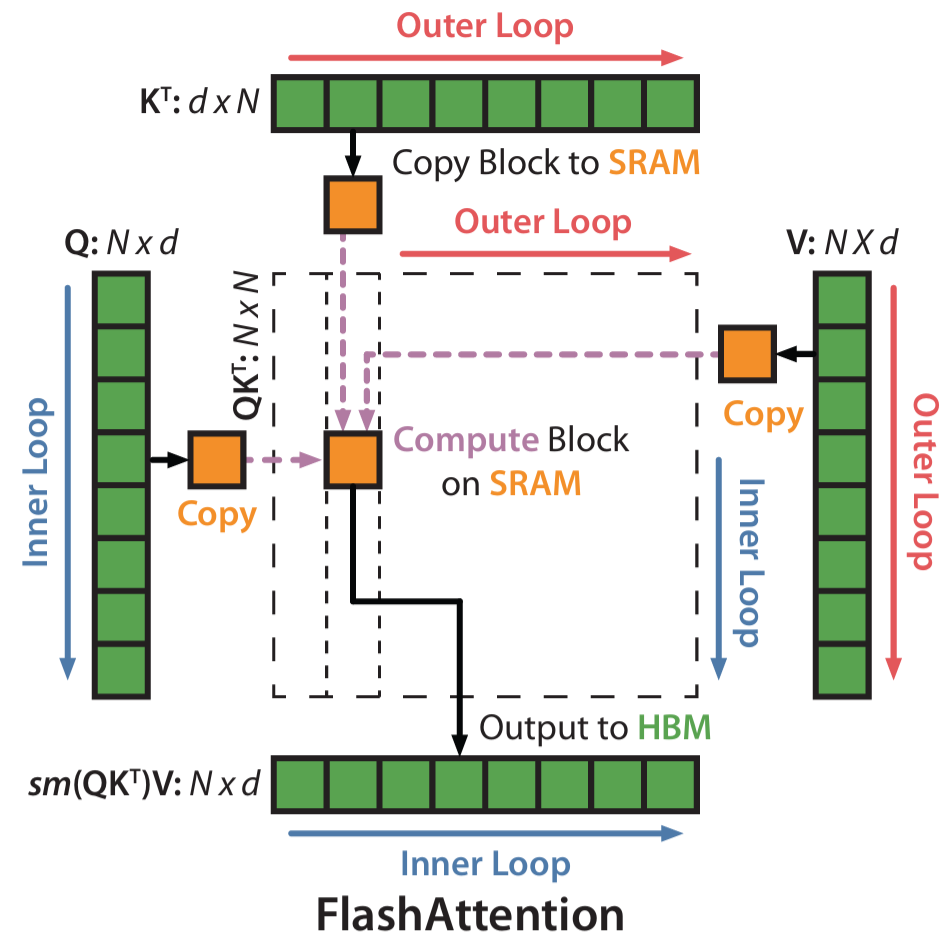
这个流程和标准 Attention 的最大区别在于,标准 Attention 是“先得到完整 \(S\),再得到完整 \(P\),最后得到 \(O\)”;而 FlashAttention-1 是“扫一块,更新一次统计量,顺便累积一部分输出”。也就是说,它不再把 softmax 看成一个必须在整张矩阵上单独完成的阶段,而是把 softmax 融入到了分块扫描的过程中。
这样做有两个好处。一个是,中间矩阵不需要落到 HBM。\(S\) 和 \(P\) 只在片上短暂存在于当前块的计算过程中,算完就可以丢弃,不需要作为完整张量写回显存。另一个是,HBM 的访问模式更接近流式扫描。每个 \(K_j, V_j\) 块被读进片上以后,会立刻参与分数计算、softmax 更新和输出累积,而不是先产生一堆中间结果再留给下一阶段处理。这样就提高了数据复用,减少了不必要的读写。而且,从结果上看,FlashAttention-1 的前向传播仍然计算的是精确的标准 Attention,而不是近似 Attention。它改变的是执行方式,不是数学定义。

接下来我们用 PyTorch 来实现一下。源代码在这里。
from flash_attention_sim import flash_attention_v1_forward
N, d = 128, 64
Q = torch.randn(N, d)
K = torch.randn(N, d)
V = torch.randn(N, d)
Br, Bc = 32, 32
O_flash = flash_attention_v1_forward(Q, K, V, Br, Bc)
# reference
scale = 1.0 / math.sqrt(d)
S = (Q @ K.T) * scale
P = S.softmax(dim=1)
O_ref = P @ V
max_err = (O_flash - O_ref).abs().max()
print('Max absolute error:', max_err.item())Max absolute error: 2.980232238769531e-07通过对比我们的仿真实现和标准 Attention 的输出,我们可以验证 FlashAttention-1 的前向传播确实得到了完全相同的结果。虽然它的执行方式和标准 Attention 看起来很不一样,但数学上它们是等价的。FlashAttention-1 只是换了一种更适合 GPU 执行的方式来计算同样的东西,从而避免了大量的 IO,达到了加速的目的。
到这里,前向传播的问题已经解决了:我们可以不用存下 \(S\) 和 \(P\),只靠 \(m\)、\(l\) 和 \(O\) 就完成输出计算。但新的问题马上出现了:反向传播怎么办?
在标准 Attention 里,反向传播通常会直接用到前向阶段保存下来的中间结果,比如 \(S\) 和 \(P\)。因为梯度公式往往依赖这些量,所以一种最直接的实现方式就是在前向传播时把它们存下来,反向传播时再拿出来用。但 FlashAttention-1 在前向时故意不保存这些 \(N\times N\) 的中间矩阵。这样一来,反向时虽然省了显存和 IO,却失去了现成的中间结果。
FlashAttention-1 的解决办法也很简单:再重新算一遍不就行了?这就是所谓的 重计算(recomputation)。
对于标准 Attention,
\[ S = QK^\top, \quad P = \mathrm{softmax}(S), \quad O = PV \]
设输出梯度为 \(dO = \frac{\partial L}{\partial O}\),那么反向传播仍然可以写成:
\[ dV = P^\top dO, \quad dP = dO V^\top \]
再经过 softmax 的反向传播,就可以得到 \(dS\),最后再传回 \(Q\) 和 \(K\):
\[ dS = dP \odot P - \mathrm{rowsum}(dP \odot P) \] \[ dQ = dS\,K, \quad dK = dS^\top Q \]
所以从数学上看,FlashAttention-1 和标准 Attention 的 backward 是一样的。真正不同的地方只在于:这些中间量不再提前存好,而是在反向时重新算出来。
还记得我们在前面提过,FlashAttention-1 的前向阶段并不保存完整的 \(S\) 和 \(P\),而是只保存了每行的最大值 \(m\)、每行的归一化和 \(l\),以及最终输出 \(O\)。到了反向传播时,我们只要按照和前向类似的顺序重新扫描 \(Q\)、\(K\) 和 \(V\),重新计算出 \(S\) 和 \(P\),就可以用这些量来计算梯度了。
对于某个块 \(Q_i\) 和 \(K_j, V_j\),反向时可以先重新计算局部分数:
\[ S_{ij} = Q_i K_j^\top \]
然后利用前向保存的 \(m_i\) 和 \(l_i\) 恢复对应的概率块:
\[ P_{ij} = \frac{\exp(S_{ij} - m_i)}{l_i} \]
也就是说,反向传播所需的 \(P_{ij}\) 并不是从 HBM 里读出来的,而是现场重算出来的。
在实现上,softmax backward 最关键的是下面这个式子:
\[ dS_{ij} = P_{ij} \odot (dP_{ij} - \delta_i), \quad \delta_i = dO_i^\top O_i \]
这个公式说明,只要我们能重算出当前块的 \(P_{ij}\),再加上每一行一个标量 \(\delta_i\),就能恢复 softmax 的梯度,而不必在前向时保存整张 \(P\)。这正是 FlashAttention-1 可以把 backward 也做成分块计算的关键。

表面上看,反向时重算 \(S_{ij}\) 和 \(P_{ij}\) 好像增加了额外计算;但从系统角度看,这通常是值得的。因为相比“前向存下来、反向再读回来”,重算虽然多做了一些 FLOPs,却省掉了大量 HBM 访问。而我们在 10.1 已经看到,Attention 的瓶颈往往不是计算,而是 IO。所以 FlashAttention-1 的这套策略本质上还是同一个思路:用更多片上计算,换更少显存读写。
接下来我们也用 PyTorch 来实现一下 FlashAttention-1 的反向传播。源代码在这里。
from flash_attention_sim import flash_attention_v1_backward
N, d = 128, 64
Br, Bc = 32, 32
Q = torch.randn(N, d, requires_grad=True)
K = torch.randn(N, d, requires_grad=True)
V = torch.randn(N, d, requires_grad=True)
scale = 1.0 / math.sqrt(d)
# reference forward
S = (Q @ K.T) * scale
P = torch.softmax(S, dim=1)
O_ref = P @ V
dO = torch.randn_like(O_ref)
O_ref.backward(dO)
dQ_ref = Q.grad.detach().clone() # type: ignore
dK_ref = K.grad.detach().clone() # type: ignore
dV_ref = V.grad.detach().clone() # type: ignore
Q = Q.detach().clone()
K = K.detach().clone()
V = V.detach().clone()
# custom backward
dQ, dK, dV = flash_attention_v1_backward(Q, K, V, dO, Br, Bc)
max_err_dQ = (dQ - dQ_ref).abs().max()
max_err_dK = (dK - dK_ref).abs().max()
max_err_dV = (dV - dV_ref).abs().max()
print('dQ max absolute error:', max_err_dQ.item())
print('dK max absolute error:', max_err_dK.item())
print('dV max absolute error:', max_err_dV.item())dQ max absolute error: 2.384185791015625e-07
dK max absolute error: 1.7881393432617188e-07
dV max absolute error: 1.9371509552001953e-07到这里,FlashAttention-1 已经完成了一件非常重要的事:它通过分块计算和 online softmax,避免了显式存储完整的注意力矩阵 \(S\) 和 \(P\),从而显著减少了 HBM 读写。这也是它相比标准 Attention 能够明显加速的根本原因。
但这并不意味着 FlashAttention-1 已经完全达到了最优。更准确地说,FA1 解决了“不要把整个 \(N\times N\) 的中间矩阵写回 HBM”这个大问题,但在 kernel 的组织方式上,仍然存在进一步优化的空间。其中一个关键问题,就出在 循环顺序 上。
在 FlashAttention-1 的前向传播里,通常会把 \(K, V\) 块放在外层循环,把 \(Q\) 块放在内层循环。也就是说,计算过程更接近下面这种结构:
FA1 pseudo code
for j in KV blocks:
for i in Q blocks:
update O_i, m_i, l_i这样安排有一个直接好处:每次把一个 \(K_j, V_j\) 块从 HBM 读入片上以后,可以让它尽可能被多个 \(Q_i\) 块复用,从而减少对 \(K, V\) 的重复读取。但代价也很明显:对于某个 \(Q_i\) 块来说,它的输出 \(O_i\) 不可能在一次内层计算后就最终确定,因为后面还要继续和很多不同的 \(K_j, V_j\) 块交互。因此,\(O_i\) 只能被不断更新:
\[ O_i^{(1)} \to O_i^{(2)} \to \cdots \to O_i^{(T)} \]
这意味着,FA1 往往需要把中间的 \(O_i\) 连同行级统计量 \(m_i, l_i\) 保留下来,以便在后续扫描新的 \(K, V\) 块时继续更新。换句话说,虽然 FA1 不再保存完整的 \(S\) 和 \(P\),但它仍然需要保存并反复读写部分输出状态。从 IO 的角度看,这当然已经比保存 \(N\times N\) 的注意力矩阵要好得多,但它依然不是最理想的组织方式。
这里的核心矛盾在于:
于是,算法就不得不在多个阶段之间保存 \(O_i\)、\(m_i\) 和 \(l_i\) 这些中间状态。
FlashAttention-2 正是沿着这个方向继续优化的。它的一个关键变化,就是重新安排循环顺序和并行策略,不再沿用 FA1 那种“\(K, V\) 在外、\(Q\) 在内”的循环方式,而是改成更适合输出块独立完成的调度方式。直观地说,就是让一个线程块尽量围绕同一个 \(Q_i\) 块工作,并在扫描完所有相关的 \(K, V\) 块之后,一次性得到最终的 \(O_i\),而不是在多个阶段之间反复把它存下来、更新。