前面我们已经见过几类生成模型。GAN 像是一场对抗游戏,让生成器一步生成出逼真的样本;AutoEncoder 在学压缩与重建;VAE 则开始显式地建模概率分布,可以从潜变量中采样;而到了 diffusion model,它的思路又很不一样:
它不是一步把图像画出来,而是从一团噪声开始,一点一点把图像洗出来。
这件事第一次听起来会有点奇怪:去噪,不就是把一张脏图变干净吗?这和生成有什么关系?为什么从纯噪声开始,反复去噪,最后就能得到一张真实图像?
这一节我们先不急着上完整推导,而是先把这个核心直觉讲清楚。你会看到,DDPM 的出发点其实非常简单:如果一步生成太难,那就把它拆成很多个简单的小步骤。
import random
import dnnlpy
import matplotlib.pyplot as plt
import torch
import torchvision.datasets as datasets
import torchvision.transforms.v2 as v2
plt.rc('figure', dpi=100)
dnnlpy.set_matplotlib_format('highdpi')
print('PyTorch version:', torch.__version__)
PyTorch version: 2.12.1+cpu
14.1.1 生成:加噪的逆过程
我们先想一个非常简单的过程。假设我们手里有一张真实图片 \(x_0\)。现在我们不断往上面加一点点高斯噪声:
- 第一步,加一点,图像变得有点模糊;
- 第二步,再加一点,细节更少;
- 第三步,再加一点,轮廓都开始消失;
- …
- 加很多很多步之后,它最终会变成一张几乎纯粹的高斯噪声图。
这说明一件事,真实数据分布和高斯噪声分布之间,也许可以通过很多个很小的变化连接起来。那么,既然我们能把一张真实图像,慢慢推到噪声那边去,那么一个自然的想法就是:
能不能反过来?
也就是说,我们能不能从纯噪声出发,每一步只做一点点修正,最后慢慢走回真实图像分布?
这就是 DDPM 最核心的想法。
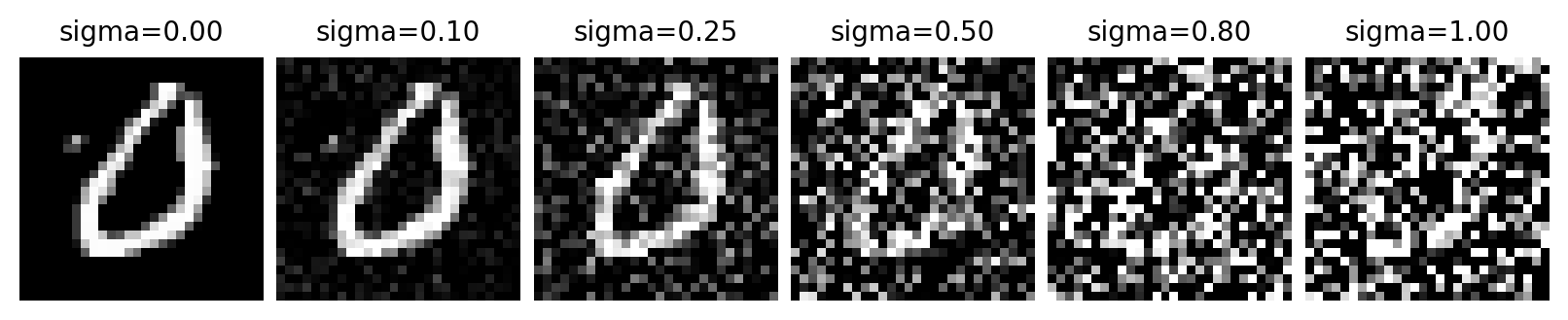
下面我们先不训练任何模型,只是拿一张图片来做一件简单的事:每隔几步,就给它加一些高斯噪声,并且噪声水平逐渐增大。我们来看看图像是如何逐渐失去结构的。
root = dnnlpy.get_data_root()
transform = v2.Compose([v2.ToImage(), v2.ToDtype(torch.float32, scale=True)])
ds = datasets.MNIST(root, train=False, download=True, transform=transform)
idx = random.randrange(len(ds))
x0 = ds[idx][0].squeeze(0) # shape: (28, 28)
noise_levels = [0.0, 0.1, 0.25, 0.5, 0.8, 1.0]
fig = plt.figure(1, figsize=(8, 2))
axes = fig.subplots(1, len(noise_levels))
for ax, sigma in zip(axes, noise_levels, strict=True):
noise = torch.randn_like(x0)
xt = x0 + sigma * noise
xt = xt.clamp(0.0, 1.0)
ax.imshow(xt, cmap='gray')
ax.axis('off')
ax.set_title(f'sigma={sigma:.2f}', fontsize=10)
fig.tight_layout(pad=0.5)
plt.show()
从上面的图里我们可以发现,当噪声很小时,图像的大体结构还在;当噪声逐渐增大时,模型需要恢复的信息越来越多;当噪声大到一定程度时,图像几乎就只剩下随机的像素点了。
所以,从清晰图像到纯噪声,不是啪地一下完成的,而是可以分成很多个小步骤。那么反过来,从噪声走回图像,是不是也有可能分成很多个小步骤呢?也就是说,我们在完成一个对加入噪声的逆过程。那么,我们为什么要一步一步加入噪声呢,而不是一步到位呢?
14.1.2 为什么一步一步容易,而一步到位难?
假设现在让你做两个任务。
任务 A:一步到位生成一张猫的图片
输入是一团随机噪声,输出直接是一张完整、自然、结构合理、细节丰富的猫图。
这很难。因为模型一次就要决定很多事情:猫的姿态是什么?脸朝哪里?背景是什么?毛发纹理怎么画?光照怎么安排?整体结构是否自然?也就是说,一步到位生成,本质上是在学习一个非常复杂的全局映射。所以,这个任务对模型来说是非常难的。
任务 B:给你一张稍微有点噪声的图,让你把噪声去掉一点
这个任务就简单很多。因为这时候图像里已经保留了一部分结构,大概的轮廓还在,局部形状还在,噪声只是覆盖在这些结构之上。就像上面的实验,即使加入 100% 的噪声,我们仍然可以大体分辨出图片里的数字。模型也是一样。这时候,模型不需要从零创造一切,它只需要知道,在这张图里,哪些部分更像是噪声?应该往哪个方向修正一点?这就比一步生成整张图容易得多。
于是,Diffusion Model 的核心策略就是:不要强迫模型一次学会从随机数直接生成图像,而是把这个难问题拆成很多个简单的小问题,每一步只去掉一点噪声。这和深度学习里一个很常见的思想很像:一个复杂映射,如果拆成很多个简单映射,往往更容易学习。
14.1.3 DDPM 的核心思路:先学破坏,再学恢复
DDPM 其实做了两件事。
第一步:设计一个前向加噪过程
我们人为规定一个简单、固定的过程,把真实图像一步步加噪,直到最后变成标准高斯噪声:
\[
x_0 \rightarrow x_1 \rightarrow x_2 \rightarrow \cdots \rightarrow x_T
\]
其中,\(x_0\) 是真实图像;\(x_t\) 是第 \(t\) 步加噪后的结果;\(x_T\) 基本上就是纯噪声。
这个过程不需要学习,是我们自己定义好的。它的作用就是,把复杂的数据分布,逐渐变成一个我们非常熟悉、非常容易采样的高斯分布。
第二步:学习一个反向去噪过程
既然前向过程会把图像变成噪声,那么我们就训练一个神经网络,去学习反方向的过程:
\[
x_T \rightarrow x_{T-1} \rightarrow x_{T-2} \rightarrow \cdots \rightarrow x_0
\]
也就是,输入当前带噪的图,预测这一步应该去掉多少噪声,得到稍微更干净一点的图;重复很多次,最后得到一张清晰图像。
于是,当我们想要生成图片时就很简单了:从一个随机高斯噪声开始,反复调用去噪网络,最后生成样本。所以,DDPM 的生成并不是像 GAN 那样直接生成,而是从噪声出发,逐步去噪。
直觉上,我们已经觉得这件事合理了。从概率建模的角度看,它其实也很自然。
我们知道,无论何种生成模型,最终想学的都是数据分布 \(p_{\text{data}}(x)\)。传统生成模型会直接或间接地去逼近这个分布,而 DDPM 是先人为定义一个前向过程,把数据分布慢慢变成高斯分布;再学习它的反向过程,让模型学会如何从高斯分布回到数据分布。
也就是说,它不是直接硬学:
\[
\text{noise} \rightarrow \text{image}
\]
而是学:
\[
\text{noise} \rightarrow \text{slightly less noisy image}
\rightarrow\cdots \rightarrow \text{clean image}
\]
每一步都只做一点点修改,因此学习难度更低,也更稳定。
所以,DDPM 成功把一个图像生成问题,转化成了一个去噪问题。我们先人为把图像变得更糟(加噪),再教网络怎么把图像变得更好(去噪)。这就是它的核心思路。每一步网络的输出,就是这一步我们应该从图片里去掉多少噪声。
14.1.4 DDPM 的训练目标:猜噪声
在最常见的 DDPM 记号里,我们会把第 \(t\) 步的带噪样本写成:
\[
x_t = \sqrt{\bar{\alpha}_t}\,x_0 + \sqrt{1 - \bar{\alpha}_t}\,\epsilon,
\qquad \epsilon \sim \mathcal{N}(0, I)
\]
这条式子现在不用急着完全吃透,我们只需要先抓住它表达的意思:
- 原图 \(x_0\) 的成分还保留了一部分;
- 高斯噪声 \(\epsilon\) 的成分加入了一部分;
- 随着 \(t\) 增大,噪声部分会越来越强;
- 当 \(t\) 足够大时,\(x_t\) 就会越来越接近纯噪声。
这里的 \(\bar{\alpha}_t\) 是一个随时间变化的系数,控制了原图和噪声的比例。它是随时间单调递减的,所以随着 \(t\) 增大,原图成分逐渐减少,噪声成分逐渐增加。它的具体形式我们后面再讲,现在先不急。
在训练时,模型的任务通常就是:
\[
\epsilon_\theta(x_t, t) \approx \epsilon
\]
也就是说,给它一张在某个时刻的含噪声图像,让它猜出其中混入的噪声。这就是为什么很多 DDPM 论文和代码实现里,最后的损失函数看起来像一个很简单的均方误差:
\[
\mathcal{L} = \mathbb{E}\left[\left\|\epsilon - \epsilon_\theta(x_t, t)\right\|^2\right]
\]
表面上它只是在猜噪声,但本质上它是在学习如何把样本从噪声方向,慢慢拉回数据分布。
14.1.5 本章小结
现在我们可以把 DDPM 的总体流程总结出来了。
训练阶段
训练时,我们拿一张真实图像 \(x_0\),随机选一个时间步 \(t\),然后:
- 按照预先定义的规则,给它加上对应强度的噪声,得到 \(x_t\);
- 把 \(x_t\) 和时间步 \(t\) 输入神经网络;
- 让网络预测这一步加入的噪声;
- 用预测噪声和真实噪声做损失,训练网络。
所以训练的本质就是,让模型学会在任意噪声水平下,识别并估计噪声。
生成阶段
生成时,我们不再输入真实图像,而是直接从纯高斯噪声 \(x_T\) 开始:
- 输入高斯噪声;
- 网络预测其中的噪声;
- 去掉一点噪声,得到更干净的图;
- 反复执行,从 \(T\) 走到 \(0\)。
最后得到的 \(x_0\),就是我们想要的生成样本。
DDPM 的本质可以理解为三句话:
- 先把真实数据一步步加噪到高斯分布;
- 再训练模型学习这个过程的逆过程;
- 于是生成时,只要从高斯噪声出发反向走回来,就能得到样本。
总的来说,DDPM 的想法就是,如果复杂的生成任务太难,那就把它拆成很多个简单的小任务。当然,虽然 DDPM 的核心思路很简单,但它的数学推导和细节设计还是非常让人头疼的,后面我们会慢慢展开来讲。
下一节我们就要正式进入数学形式,来看看 DDPM 的前向加噪和反向去噪是怎么定义的,以及它们之间的关系。到最后你就会发现,原来 DDPM 的训练目标和生成流程,都是从一个非常自然的概率建模角度推导出来的,而不是随意设计的。