11.1 从 CNN 到 Vision Transformer:把图像当成序列
在前面的章节里,我们已经看到 Transformer 如何处理序列。无论是机器翻译里的 Encoder-Decoder Transformer,还是只使用 encoder 或 decoder 的模型,它们的输入本质上都是一个 token 序列:
\[ X = [x_1, x_2, \dots, x_n] \]
如果输入是序列,这件事非常自然。句子本来就是一个词接一个词,代码本来就是一个符号接一个符号,语音也可以按照时间展开成音频序列。所以,模型只需要把每个 token 映射成向量,再交给 self-attention 处理即可。
但是图像不一样。一张图像通常是一个三维张量:
\[ X \in \mathbb{R}^{C \times H \times W} \]
其中,\(C\) 是通道数,\(H\) 和 \(W\) 是图像的高度和宽度。它看起来不是一串 token,而是一个二维空间结构。每个像素既有数值,也有空间位置;相邻像素之间通常高度相关,物体也往往由局部纹理、边缘、部件逐渐组合而成。
所以,如果我们想把 Transformer 用到图像上,面对的第一个问题就是:
Transformer 只能处理 token 序列,图像又不是序列,那我们该怎么办?
Vision Transformer,简称 ViT (Dosovitskiy et al. 2021),正是从这个问题出发的。它的想法其实很简单:既然 Transformer 擅长处理 token 序列,那我们不如就把一张图像切成一组小块,把每个小块当成一个 token,然后用 Transformer 来建模这些图像 token 之间的关系,不就行了么?
这一节我们先不急着写完整的 ViT 结构,而是先理解它为什么会这样设计。也就是说,我们要从 CNN 的图像建模方式出发,逐步走到 ViT 的基本想法:把图像当成序列来处理。
11.1.1 为什么图像一直适合用 CNN 处理
在 ViT 出现之前,卷积神经网络(Convolutional Neural Network, CNN)长期是视觉任务中的主流架构。CNN 之所以适合图像,并不是偶然的,而是因为它的结构里内置了一些非常符合图像特点的假设。
第一个假设是局部性(locality)。图像里的一个像素通常和它周围的像素关系密切,而不是和很远处的像素关系密切。比如边缘、纹理、角点,往往都可以通过局部区域识别出来。因此,CNN 使用小的卷积核,例如 \(3 \times 3\) 或 \(5 \times 5\),先从局部区域提取特征。
第二个假设是平移等变性(translation equivariance)。在 CNN 里,同一个卷积核会在整张图像上滑动。也就是说,模型用同一组参数去检测不同位置上的相似模式。如果一个卷积核学会了检测垂直边缘,那么它不只可以在左上角检测垂直边缘,也可以在右下角检测垂直边缘。这符合图像任务中的一个直觉:同一种视觉模式可能出现在图像的不同位置。这也是 CNN 的参数共享机制。
第三个假设是层级结构(hierarchical structure)。浅层卷积通常学习边缘、颜色、纹理等低级特征;更深的层逐渐组合这些低级特征,形成部件、物体甚至场景级别的表示。随着网络加深,每个位置的感受野逐渐扩大,模型也就可以从局部信息逐步整合出全局语义。比如,在一张猫的图片里,猫耳朵附近的像素会组成局部边缘和纹理;猫脸附近的局部区域会组成眼睛、鼻子、胡须等结构;多个局部结构再组合起来,才形成“猫”这个整体概念。
因此,CNN 看图像的方式大致可以理解为:
先看局部,再通过层层堆叠逐渐扩大视野。
这套设计非常适合图像,也非常高效。卷积层不需要让每个位置从一开始就和所有位置交互,而是先关注附近区域,再通过多层网络逐步传播信息。很多经典视觉模型,例如 AlexNet、VGG、ResNet,都建立在这个思路之上。
但是,这也带来了一个自然的问题:如果图像中的两个区域相距很远,但它们在语义上高度相关,CNN 需要经过很多层才能让它们充分交换信息。那么,有没有一种结构,可以让图像中的任意两个区域从一开始就直接交互?
这正是 self-attention 擅长的事情。
11.1.2 Self-Attention:另一种图像建模方式
在 Transformer 里,self-attention 的核心作用是让序列中的每个 token 都可以根据当前需要,从其他 token 中检索信息。对于一个长度为 \(n\) 的序列,每个 token 理论上都可以直接关注序列中的任意其他 token。
如果把这个思想搬到图像上,就会得到一个很有吸引力的想法:图像中的每个区域不一定非要先通过局部卷积逐层扩大感受野,它也可以直接和其他区域建立关系。
比如,在一张动物图片里,头部、身体和尾巴可能相隔较远。CNN 通常需要通过多层卷积逐渐把这些部件的信息整合起来。而如果使用 self-attention,表示头部的图像 token 可以直接关注表示身体或尾巴的 token。模型不必等到很多层之后才获得全局信息,而是在每一层中都可以进行全局的信息交互。
当然,这就又绕回了我们最开始的问题:
Self-attention 的输入是 token 序列,可图像不是现成的 token 序列。
如果我们想让图像进入 Transformer,就必须先搞清楚一个事儿:图像里的 token 到底是什么?
可能有的人就会说了,token 是一个句子最基本的组成单元,像素是图像的基本组成单元。那我们直接把每个像素当成一个 token 不就行了?
想法是好的。可是,如果这样,一张 \(224 \times 224\) 的图像就会变成 \(224 \times 224 = 50176\) 个 token。我们知道,self-attention 需要计算所有 token 两两之间的关系,attention 矩阵大小会随着 token 数量平方增长。如果有 50176 个 token,那么 attention 矩阵会非常巨大,计算和显存开销都难以接受。以 float32 类型为例,这个 attention 矩阵大约需要 10GB 内存。这还只是一个 attention 矩阵,更别说我们还要堆叠多个层了。
所以,ViT 没有把单个像素当成 token。它采用了一个折中的选择:把图像切成一组小块(通常是正方形),每个小块叫做一个 patch,然后把每个 patch 当成一个 token。
这一步非常关键。它把图像从二维网格变成了一个 token 序列,既不让 token 数量过多,也让 Transformer 可以直接接手后面的建模。
11.1.3 把图像切成 Patch
假设我们有一张图像:
\[ X \in \mathbb{R}^{C \times H \times W} \]
假设 patch size 为 \(P\),也就是每个 patch 的大小是 \(P \times P\)。如果 \(H\) 和 \(W\) 都可以被 \(P\) 整除,那么整张图像可以被切成
\[ N = \frac{H}{P} \times \frac{W}{P} \]
个 patch。
例如,一张 \(224 \times 224\) 的 RGB 图像,如果设置 \(16 \times 16\) 的 patch,那么 patch 数量就是:
\[ N = \frac{224}{16} \times \frac{224}{16} = 14 \times 14 = 196 \]
这样,原本有 50176 个像素位置的图像,就被转换成了 196 个 patch token。这个序列长度对 Transformer 来说就合理得多。
此时,每个 patch 本身仍然是一个小图像块。对于 RGB 图像,一个 patch 的形状是:
\[ (C, P, P) \]
如果把它展平成一个向量,我们就会得到:
\[ x_i \in \mathbb{R}^{C \times P^2} \]
于是,一张图像可以表示成一组 patch 向量:
\[ \text{image} \rightarrow [x_1, x_2, \dots, x_N] \]
到这里,图像终于变成了一个序列。只不过,这个序列里的 token 不是词,而是图像 patch。
从直觉上说,ViT 做了一件很简单但很关键的事情:
把图像中的局部区域当成视觉 token。
这样一来,Transformer 就不再只能处理语言序列。只要我们能把输入拆成一组 token,它就可以用 self-attention 去建模 token 之间的关系。我们后面几节要讲的 patch embedding、class token、positional embedding 和 ViT Encoder,都是围绕这句话展开的。
11.1.4 Patch 序列和词序列有什么不同?
虽然 ViT 把图像变成了 token 序列,但图像 patch 序列和自然语言词序列并不完全一样。
在语言中,token 的顺序通常具有很强的一维结构。一个词的前后顺序会直接影响句子的含义。例如 “dog bites man” 和 “man bites dog” 的词相同,但顺序不同,语义就不同。
图像也有位置结构,但它原本是二维的。一个 patch 不仅有前后关系,还有上下左右关系。把二维 patch 网格展平成一维序列以后,原来的空间结构会被弱化。比如左上角和右下角的 patch,在序列里只是两个位置;模型如果没有额外信息,并不知道它们原本在图像中的具体空间关系。
这会带来一个新的问题:
如果图像被展平成序列,模型还知道每个 patch 原本在哪里吗?
答案是:只靠 patch 内容本身是不够的。两个 patch 即使内容相同,如果一个来自图像左上角,另一个来自图像右下角,它们在视觉语义上也可能扮演不同角色。因此,ViT 后面还需要加入位置编码,把 patch 的空间位置信息补回来。
不过,在进入位置编码之前,我们还要先解决另一个问题:展平后的 patch 向量只是原始像素的排列,它还不是 Transformer 真正使用的 token embedding。
在 NLP 中,token ID 会先经过 embedding 层,变成一个固定维度的向量。类似地,图像 patch 展平以后,也需要经过一个可学习的线性投影,变成 Transformer 使用的 patch embedding。
为什么要这样做呢?因为展平只是把像素重新排列成一个向量,它本身并没有学习能力。比如一个 \((3, 16, 16)\) 的 patch 展平以后得到 768 维向量,但这个向量只是原始像素值的排列形式,并没有经过特征变换。所以,我们要把它投影到特征空间,让模型更好地捕捉 patch 之间的语义关系,而不是被原始像素值的排列所限制。
总的来说,ViT 的输入构造大致包含三步:
- 把图像切成 patch,并把每个 patch 展平成向量;
- 把每个 patch 向量投影到 Transformer 的隐藏维度,得到 patch embedding;
- 给每个 patch embedding 加上位置编码,让模型知道它们来自图像中的哪里。
这就是我们后面几节要详细讨论的内容。
11.1.5 ViT 的整体思路
现在,我们可以先从整体上看一下 ViT 的结构。它并不是为图像重新发明一套完全不同的 Transformer,而是尽量复用标准 Transformer Encoder。真正关键的变化发生在输入端:ViT 先把图像转换成一个 patch token 序列。
整体流程可以概括为:
\[ \begin{aligned} \text{image} & \rightarrow \text{patches} \\ & \rightarrow \text{patch embedding} \\ & \rightarrow \text{add class token} \\ & \rightarrow \text{add positional embedding} \\ & \rightarrow \text{Transformer Encoder} \\ & \rightarrow \text{class token output} \\ & \rightarrow \text{classification head} \end{aligned} \]
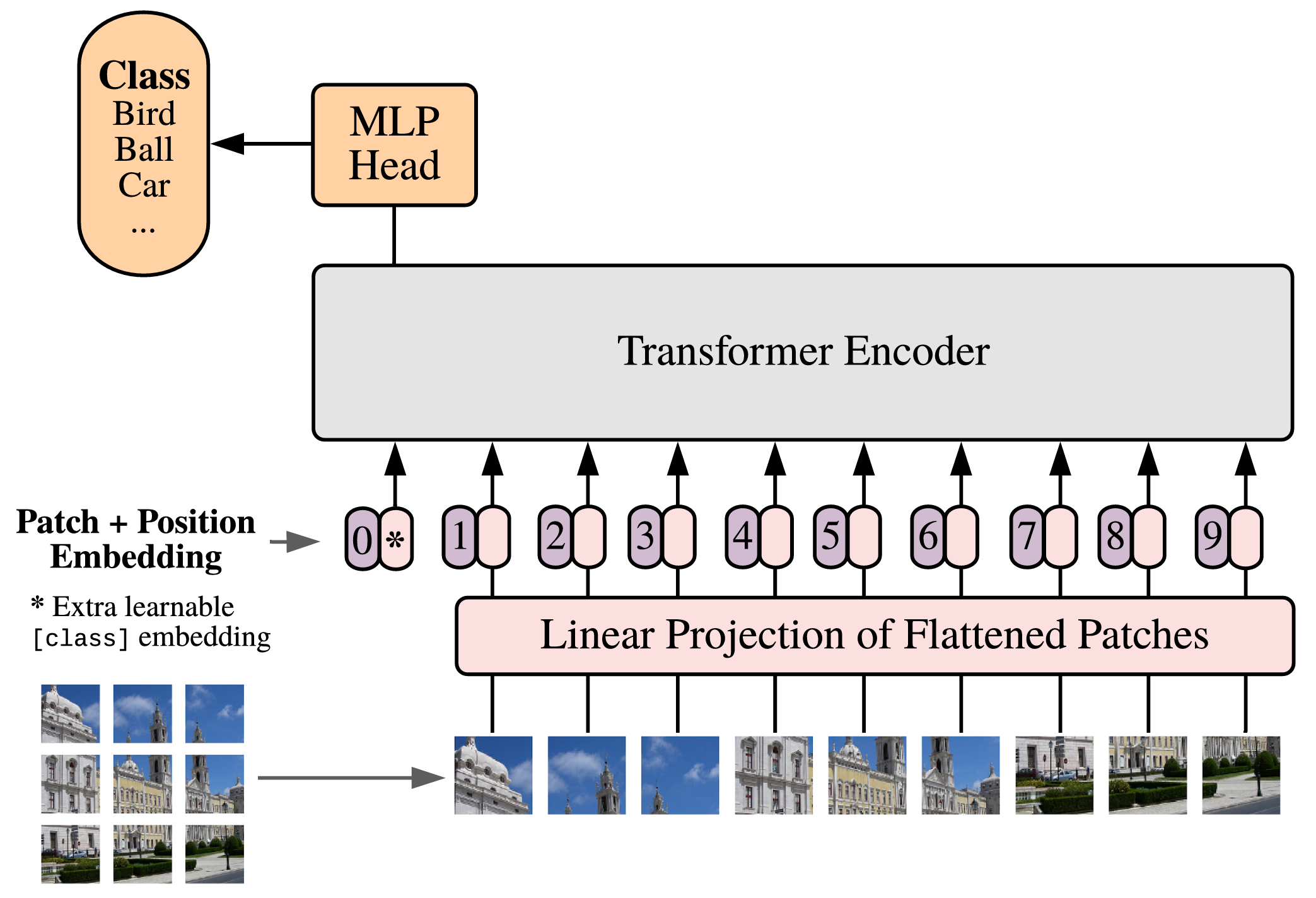
给定一张图像,ViT 会先把它切成多个 patch;然后把每个 patch 展平,并通过线性层映射成一个固定维度的向量;接着加入位置编码,让模型知道每个 patch 来自哪里;最后,把这些 patch embedding 输入 Transformer Encoder,通过 self-attention 建模不同 patch 之间的关系。
如果任务是图像分类,模型还需要得到一个整张图像的表示。原始 ViT 的做法是加入一个额外的 class token,让这个 token 在多层 self-attention 中和所有 patch token 交互,最后用它的输出表示进行分类。当然,也可以不使用 class token,直接对所有 patch token 的输出进行平均池化,也是可以的。
所以,ViT 的核心模块可以按下面的问题依次理解:
- 图像怎么变成 token 序列?切成 patch。
- 每个 patch 怎么变成 Transformer 能处理的向量?做 patch embedding。
- 展平成序列后,模型怎么知道 patch 的位置?加入 positional embedding。
- 怎样得到整张图像的表示?加入 class token 或使用 average pooling。
- Patch 之间如何交换信息?使用 Transformer Encoder 中的 self-attention。
可以看到,ViT 的设计并不是一堆模块的简单堆叠。每个模块都是为了解决“把图像交给 Transformer”过程中遇到的具体问题。
11.1.6 CNN 和 ViT 的核心差异
理解 ViT 时,一个常见误区是把它简单看成直接用 Transformer 替换 CNN。这样说虽然不算完全错,但太简单了。更准确地说,CNN 和 ViT 对图像结构的假设不同。
| 模型 | 基本单位 | 信息交互方式 | 主要归纳偏置 |
|---|---|---|---|
| CNN | 像素邻域 / 局部特征 | 局部卷积逐层扩大感受野 | 局部性、参数共享、层级结构 |
| ViT | 图像 patch | patch 之间的 self-attention | 更弱的视觉先验,更直接的全局交互 |
CNN 的图像建模方式更依赖视觉先验。它假设局部邻域很重要,假设相同模式可以出现在不同位置,也假设复杂语义可以由简单局部特征逐层组合出来。这些先验让 CNN 在数据量不那么大的情况下也能训练得很好,因为模型不需要从零开始学习所有图像结构。
ViT 的先验更弱。它不直接规定每个 patch 只能先看附近的 patch,也不强制使用局部卷积来逐层扩大感受野。它把图像切成 patch 序列后,让 self-attention 自己学习 patch 之间应该如何交互。这样做更灵活,也更容易扩展到大规模数据和大模型,但同时也意味着模型需要从数据中学到更多视觉规律。
这也是为什么原始 ViT 在大规模数据上表现很好,但在较小数据集上不一定天然优于 CNN。ViT 的优势来自更通用的序列建模方式和更好的可扩展性。但是,它也需要大量数据和适当的训练策略来充分发挥潜力。
11.1.7 本章小结
这一节,我们从 CNN 的图像建模方式出发,讨论了 Vision Transformer 的基本动机。
CNN 非常适合图像,因为它利用了局部性、权重共享和层级结构等视觉先验。它通常从局部区域开始提取特征,再通过多层堆叠逐渐扩大感受野,整合全局信息。Self-attention 则提供了另一种思路:让不同位置的表示可以直接交互,从而更灵活地建模长距离关系。
但是,Transformer 的输入是 token 序列,而图像原本是二维网格。ViT 的关键一步,就是把图像切成 patch,并把每个 patch 当成一个视觉 token。这样,图像就可以被表示为一个 patch 序列,再交给 Transformer Encoder 处理。
因此,ViT 的核心不是简单地把 CNN 换成 Transformer,而是先把图像重新组织成序列,再用 self-attention 建模 patch 之间的关系。接下来,我们会详细讨论第一步:patch embedding。也就是,我们该如何把图像中的 patch 转换成 Transformer 可以处理的 token embedding。