import torch
import torch.nn as nn
from torch import Tensor
print('PyTorch version:', torch.__version__)PyTorch version: 2.12.0+xpu在上一节里,我们讨论了 Vision Transformer 的基本想法:既然 Transformer 擅长处理序列,那么能不能把图像也变成一个序列,再交给 Transformer 来建模?
这个想法听起来很自然,但它马上带来一个具体问题:Transformer 接收的不是原始图像,而是 token embedding 序列。在自然语言处理中,输入通常是一串 token,每个 token 会被映射成一个 embedding;而图像原本是一个二维网格,并没有现成的 token。
因此,ViT 的第一步不是 self-attention,而是先做一次输入转换:
\[ \text{image} \quad \longrightarrow \quad \text{patch token sequence} \]
这一节我们只关注这一步,也就是 patch embedding。它要回答的问题是:
如何把一张图像转换成 Transformer 可以处理的 token embedding 序列?
import torch
import torch.nn as nn
from torch import Tensor
print('PyTorch version:', torch.__version__)PyTorch version: 2.12.0+xpu我们先回忆一下 Transformer 的输入形式。对于一个长度为 \(N\) 的序列,输入通常可以写成:
\[ X = [x_1, x_2, \dots, x_N] \]
其中,每个 token embedding 都是一个 \(D\) 维向量:
\[ x_i \in \mathbb{R}^{D} \]
如果使用 batch-first 的形式,输入张量的形状就是:
\[ X \in \mathbb{R}^{B \times N \times D} \]
其中,\(B\) 是 batch size,\(N\) 是序列长度,\(D\) 是 embedding dimension。
也就是说,Transformer 期待的是这样一种输入:
一组 token,每个 token 是一个向量。但是一张图像通常是:
\[ X \in \mathbb{R}^{B \times C \times H \times W} \]
其中,\(C\) 是通道数,\(H\) 和 \(W\) 分别是图像的高度和宽度。
这两个张量的含义完全不同。图像是一个二维空间网格,每个位置上有多个颜色通道;Transformer 则希望看到一个一维 token 序列,每个 token 已经是一个固定维度的向量。
所以,patch embedding 要做的事情可以概括成:
\[ \mathbb{R}^{B \times C \times H \times W} \quad \longrightarrow \quad \mathbb{R}^{B \times N \times D} \]
这里的 \(N\) 是图像被切成 patch 之后得到的 token 数量,\(D\) 是 Transformer 使用的 embedding dimension。
换句话说,patch embedding 是 ViT 的输入翻译器。它把图像从视觉空间中的二维网格,翻译成 Transformer 熟悉的 token embedding 序列。
现在,我们来正式介绍一下 patch embedding。它是 ViT 输入部分的第一个设计,也是最核心的设计之一。
我们可以把 patch embedding 分成两步:
第一步是把图像切成一组不重叠的小块。假设输入图像大小是 \(H \times W\),patch size 是 \(P \times P\)。为了简单起见,我们先假设 \(H\) 和 \(W\) 都可以被 \(P\) 整除。那么,高度方向有 \(\frac{H}{P}\) 个 patch,宽度方向有 \(\frac{W}{P}\) 个 patch。所以总的 patch 数量是:
\[ N = \frac{H}{P} \times \frac{W}{P} \]
第二步是把每个 patch 变成一个向量。对于 RGB 图像,一个 patch 的形状是:
\[ (C, P, P) \]
把它展平以后,我们就会得到一个长度为 \(C \times P^2\) 的向量。然后再用一个线性层,把这个向量投影到 Transformer 使用的 embedding 维度 \(D\):
\[ C \times P^2 \rightarrow D \]
如果把 batch 维度和所有 patch 放在一起,patch embedding 的整体形状变化就是:
\[ (B, C, H, W) \rightarrow (B, N, C \times P^2) \rightarrow (B, N, D) \]
这里的每个 \(D\) 维向量,就是一个 patch token,也可以叫一个 视觉 token。
举个例子。对于一张 \(224 \times 224\) 的 RGB 图像,如果 patch size 是 \(16 \times 16\),那么 patch 网格大小是:
\[ \frac{224}{16} \times \frac{224}{16} = 14 \times 14 \]
也就是说,一张图像会被切成 196 个 patch。每个 patch 原本是一个形状为 \((3, 16, 16)\) 的小图像块,展平后是 \(3 \times 16 \times 16 = 768\) 维向量。
如果我们把 embedding 维度也设为 \(D = 768\),那么输出就是:
\[ (B, 3, 224, 224) \rightarrow (B, 196, 768) \]
这就是原始 ViT (Dosovitskiy et al. 2021) 中非常常见的设置。
我们先用最直观的方式实现 patchify,把图像从原始输入变成 patch embedding。这里的目标不是追求最高效率,而是看清楚张量形状是如何变化的。
假设输入图像的形状是 \((B, C, H, W)\),我们希望把它切成大小为 \(P \times P\) 的 patch(假设可以整除),然后展平成 \((B, N, C P^2)\)。其中,\(N\) 是 patch 数量,\(C P^2\) 是每个 patch 展平后的维度。
def patchify(x: Tensor, patch_size: int) -> Tensor:
batch_size, channels, height, width = x.size()
if height % patch_size != 0 or width % patch_size != 0:
raise AssertionError(
'Image height and width must be divisible by `patch_size`.'
)
num_patches_h = height // patch_size
num_patches_w = width // patch_size
# (B, C, num_patches_h, W, patch_size)
x = x.unfold(2, patch_size, patch_size)
# (B, C, num_patches_h, num_patches_w, patch_size, patch_size)
x = x.unfold(3, patch_size, patch_size)
# (B, num_patches_h, num_patches_w, C, patch_size, patch_size)
x = x.permute(0, 2, 3, 1, 4, 5)
# NOTE: We can't use `view` here because the tensor is not
# contiguous after `permute`.
# (B, num_patches_h * num_patches_w, C * patch_size * patch_size)
x = x.reshape(batch_size, num_patches_h * num_patches_w, -1)
return x我们用一个小例子来看一下输出形状:
patch_size = 8
x = torch.randn(2, 3, 32, 32)
patches = patchify(x, patch_size)
print('Input shape:', x.shape)
print('Patch shape:', patches.shape)Input shape: torch.Size([2, 3, 32, 32])
Patch shape: torch.Size([2, 16, 192])在这个例子里,图像大小是 \(32 \times 32\),patch 大小是 \(8 \times 8\)。所以每张图像有
\[ \frac{32}{8} \times \frac{32}{8} = 4 \times 4 = 16 \]
个 patch,每个 patch 展平后的维度是
\[ 3 \times 8 \times 8 = 192 \]
因此最终输出形状是 (2, 16, 192)。
这里最容易混乱的是 unfold 和 permute。我们可以分三步理解。
第一步,用 unfold 把高度和宽度分别拆开。一部分表示“这是第几个 patch”,另一部分表示“这是 patch 里面的第几个像素”:
\[ (B, C, H, W) \xrightarrow{\operatorname{unfold}(2, P, P)} \left(B, C, \frac{H}{P}, W, P\right) \xrightarrow{\operatorname{unfold}(3, P, P)} \left(B, C, \frac{H}{P}, \frac{W}{P}, P, P\right) \]
第二步,用 permute 调整维度顺序。我们希望先按 patch 在原图中的网格位置排列(也就是 \(\frac{H}{P}\) 和 \(\frac{W}{P}\)),然后再放每个 patch 内部自己的内容(也就是通道维度 \(C\) 和 patch 内部的 \(P \times P\) 空间位置):
\[ \left(B, C, \frac{H}{P}, \frac{W}{P}, P, P\right) \rightarrow \left(B, \frac{H}{P}, \frac{W}{P}, C, P, P\right) \]
第三步,把二维 patch 网格展平成一维序列,同时把每个 patch 内部展平成向量:
\[ \left(B, \frac{H}{P}, \frac{W}{P}, C, P, P\right) \rightarrow (B, N, C P^2) \]
这样,我们就得到了一个 patch 序列。
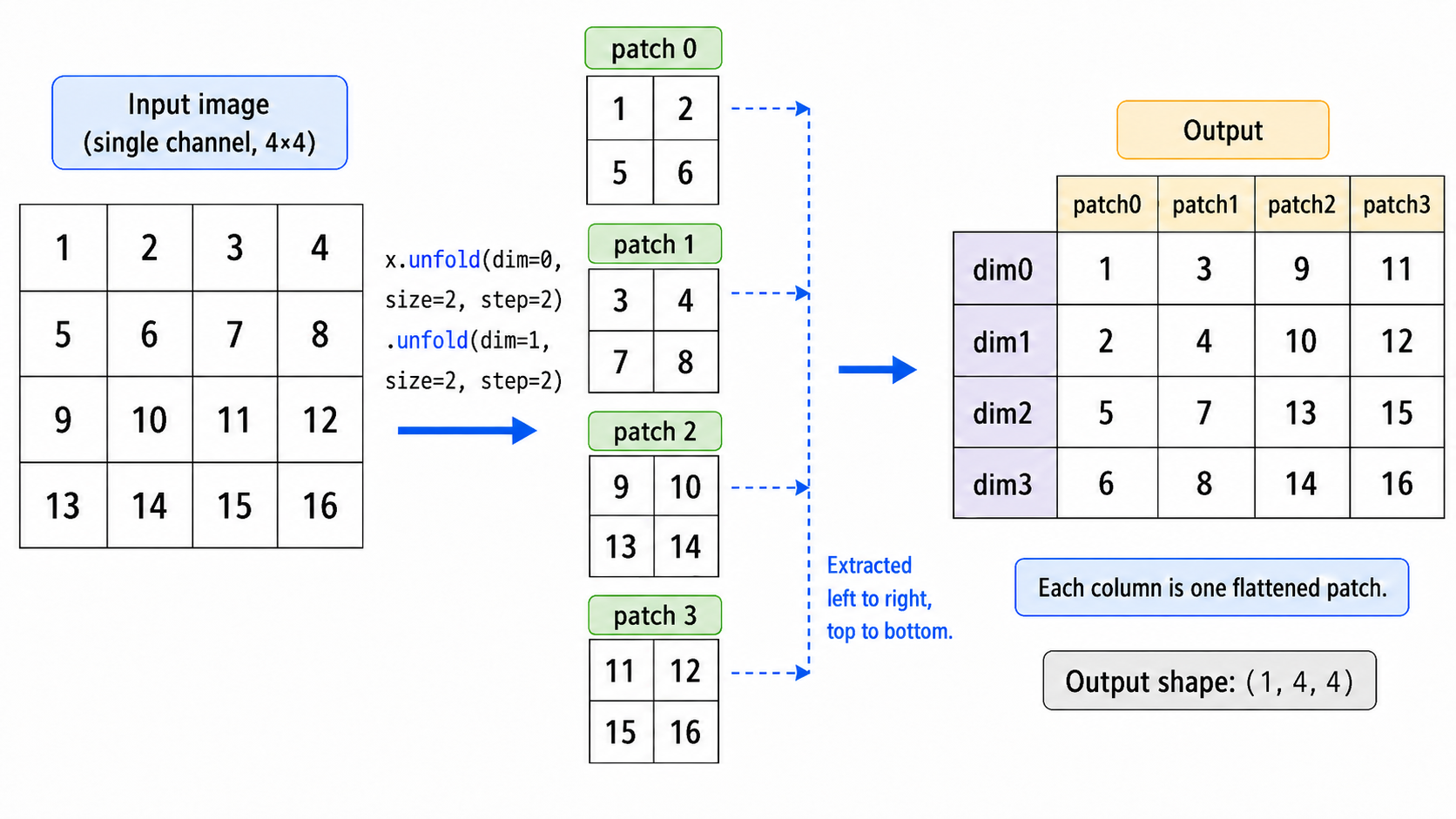
Tensor.unfold(dim, size, step) 会沿着第 dim 个维度取滑动窗口,其中 size 是窗口长度,step 是窗口步长。每取到一个窗口,它就把这个窗口摞起来,多出的维度表示这是第几个窗口。
相比使用两次 Tensor.unfold,我们也可以直接使用 nn.Unfold(kernel_size=P, stride=P)。它会直接输出一个形状为 \((B, C P^2, N)\) 的张量,只需要转置一下维度,就能得到 \((B, N, C P^2)\)。
Linear 实现 Patch Embeddingpatchify 只完成了第一步:
\[ (B, C, H, W) \rightarrow (B, N, C P^2) \]
接下来,我们需要用一个线性层把每个 patch 向量投影到 embedding 维度 \(D\):
\[ (B, N, C P^2) \rightarrow (B, N, D) \]
这就是最直观的 patch embedding 实现。
class ViTLinearPatchEmbedding(nn.Module):
def __init__(
self,
image_size: int = 224,
patch_size: int = 16,
in_channels: int = 3,
embed_dim: int = 768,
):
super().__init__()
if image_size % patch_size != 0:
raise AssertionError('`image_size` must be divisible by `patch_size`.')
self.image_size = image_size
self.patch_size = patch_size
self.num_patches = (image_size // patch_size) ** 2
self.proj = nn.Linear(in_channels * patch_size * patch_size, embed_dim)
def forward(self, x: Tensor) -> Tensor:
patches = patchify(x, self.patch_size)
embeddings = self.proj(patches)
return embeddings测试一下输出形状:
patch_embed = ViTLinearPatchEmbedding(
image_size=32,
patch_size=8,
in_channels=3,
embed_dim=64,
)
x = torch.randn(2, 3, 32, 32)
out = patch_embed(x)
print('Patch embedding output shape:', out.shape)
print('Number of patches:', patch_embed.num_patches)Patch embedding output shape: torch.Size([2, 16, 64])
Number of patches: 16这说明,每张图像被切成 16 个 patch,每个 patch 被映射成一个 64 维 token embedding。
到这里,图像已经变成了 Transformer 可以接收的序列形式:
\[ (B, C, H, W) \rightarrow (B, N, C P^2) \rightarrow (B, N, D) \]
Conv2d 实现 Patch Embedding上面的实现非常符合直觉,但实际 ViT 代码里更常见的写法是用 nn.Conv2d 实现 patch embedding。这看起来有点奇怪:ViT 不是想摆脱 CNN 吗?为什么输入层又用了卷积?
关键在于,这里的卷积不是用来堆叠局部特征提取器,而是用来高效完成:
\[ \text{patchify} + \text{linear projection} \]
如果我们使用一个卷积层:
nn.Conv2d(
in_channels=C,
out_channels=D,
kernel_size=P,
stride=P,
)那么它会在图像上以 \(P\) 为步幅滑动一个 \(P \times P\) 的卷积核。因为 kernel_size = stride = patch_size,所以这些窗口刚好是不重叠的 patch。
对于每一个 patch,卷积层会把形状为 \((C, P, P)\) 的局部区域映射成一个 \(D\) 维输出。这个过程和“展平 patch 后接一个线性层”在形式上是等价的:
\[ \text{patchify} + \text{Linear} \quad \Longleftrightarrow \quad \operatorname{Conv2d}(\text{kernel\_size}=P, \text{stride}=P) \]
下面是用 Conv2d 实现的 patch embedding:
class ViTConvPatchEmbedding(nn.Module):
def __init__(
self,
image_size: int = 224,
patch_size: int = 16,
in_channels: int = 3,
embed_dim: int = 768,
):
super().__init__()
if image_size % patch_size != 0:
raise AssertionError('`image_size` must be divisible by `patch_size`.')
self.image_size = image_size
self.patch_size = patch_size
self.num_patches = (image_size // patch_size) ** 2
self.proj = nn.Conv2d(
in_channels=in_channels,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size,
)
def forward(self, x: Tensor) -> Tensor:
x = self.proj(x)
x = x.flatten(2)
x = x.transpose(1, 2)
return x测试一下:
patch_embed = ViTConvPatchEmbedding(
image_size=32,
patch_size=8,
in_channels=3,
embed_dim=64,
)
x = torch.randn(2, 3, 32, 32)
out = patch_embed(x)
print('Patch embedding output shape:', out.shape)
print('Number of patches:', patch_embed.num_patches)Patch embedding output shape: torch.Size([2, 16, 64])
Number of patches: 16这里 Conv2d 的输出形状是:
\[ \left(B, D, \frac{H}{P}, \frac{W}{P}\right) \]
这仍然是一个二维特征图。为了交给 Transformer,我们需要把后两个空间维度展平成序列长度:
x = x.flatten(2) # (B, D, H/P * W/P)
x = x.transpose(1, 2) # (B, N, D)最终得到的形状仍然是:
\[ (B, N, D) \]
所以,用 Conv2d 写 patch embedding 只是一个更简洁、更高效的工程实现。这里的卷积层只负责把图像切成 patch token,而不是像 CNN 那样通过多层局部卷积逐步提取层级特征。
Linear 和 Conv2d 是等价的?我们可以更具体地理解一下 Linear 版本和 Conv2d 版本的关系。
对于一个 patch,展平后是一个向量:
\[ x_i \in \mathbb{R}^{C P^2} \]
线性层的权重是:
\[ W \in \mathbb{R}^{D \times C P^2} \]
输出是:
\[ z_i = W x_i + b \]
而在 Conv2d 中,每个输出通道都有一个大小为 \((C, P, P)\) 的卷积核。如果把这个卷积核展平,它同样是一个长度为 \(C P^2\) 的向量。对某个 patch 做卷积,本质上就是用这个展平后的卷积核和 patch 向量做内积。同时,由于一共有 \(D\) 个输出通道,所以就相当于有 \(D\) 个这样的线性投影方向。把它们放在一起,就等价于一个从 \(C P^2\) 到 \(D\) 的线性层。
因此,Linear 和 Conv2d 在数学上是等价的。它们都完成了从原始图像到 patch embedding 的转换:
patchify + Linear 更符合概念,适合教学;Conv2d(kernel_size=P, stride=P) 更简洁,也更接近很多实际 ViT 实现。当然,我们也可以手动把 Linear 的权重复制到 Conv2d 里,验证两者输出一致。感兴趣的读者可以自己动手试一下。
在 ViT 中,patch size 不只是一个实现细节,它会直接影响 ViT 的计算量和建模方式。
假设图像大小固定为 \(H \times W\),patch size 是 \(P\),那么序列长度是:
\[ N = \frac{H}{P} \times \frac{W}{P} \]
如果 \(P\) 变小,patch 数量会增加,序列会变长。这样每个 token 覆盖的局部区域更小,图像细节保留得更多,但 self-attention 的计算和内存开销也会明显增加;如果 \(P\) 变大,patch 数量会减少,序列会变短。这样计算更便宜,但每个 token 覆盖的区域更大,细粒度空间信息可能会损失更多。
例如,对于 \(224 \times 224\) 的图像:
| Patch size | Patch 网格 | 序列长度 \(N\) | 单头 Attention 矩阵大小 |
|---|---|---|---|
| \(8 \times 8\) | \(28 \times 28\) | \(784\) | 约 2.35 MB |
| \(16 \times 16\) | \(14 \times 14\) | \(196\) | 约 0.15 MB |
| \(32 \times 32\) | \(7 \times 7\) | \(49\) | 约 0.009 MB |
这里的 attention 矩阵大小按 \(N \times N\) 个 float32 元素估算。由于 attention 矩阵大小大约和 \(N^2\) 成正比,所以从 \(16 \times 16\) patch 改成 \(8 \times 8\) patch,不只是序列长度变成 4 倍,attention 矩阵规模会变成大约 16 倍。这也是为什么原始 ViT 中常见的设置是 patch_size=16。它在序列长度、计算成本和图像细节之间提供了一个比较实用的折中。
当然,patch size 并不是越小越好,也不是越大越好。它和数据规模、模型大小、任务类型、输入分辨率都有关系。对于图像分类,较大的 patch 有时已经足够;对于检测和分割这类密集预测任务,细粒度空间信息更加重要,因此直接使用普通 ViT 结构会遇到一些困难。这些问题我们会在后面讨论视觉 Transformer 变体时再展开。
这一节我们解决了 ViT 输入部分的第一个问题:图像如何变成 Transformer 可以接收的 token 序列?
Patch embedding 做了两件事:
因此,它完成了下面的转换:
\[ (B, C, H, W) \rightarrow (B, N, C P^2) \rightarrow (B, N, D) \]
在实现上,patch embedding 可以用两种方式完成。第一种是显式地 patchify,然后接 Linear;第二种是使用 Conv2d(kernel_size=P, stride=P)。后者在数学上等价于手动切 patch + 线性投影,也是实际实现中更常见的写法。
到这里,图像已经被翻译成了一串 patch token。但是,这还不是 ViT Encoder 的完整输入。
原因有两个。第一,patch token 只表示局部图像块。对于图像分类任务,我们还需要一个能够代表整张图像的全局表示;第二,patch 被拉平成一维序列以后,原来的二维空间位置被弱化了。Transformer 看到的是一串向量,但它不会天然知道某个 patch 来自左上角、中心还是右下角。
所以,下一节我们会继续补上两个设计:class token 和 positional embedding。前者解决“谁代表整张图”的问题,后者解决“每个 patch 来自哪里”的问题。