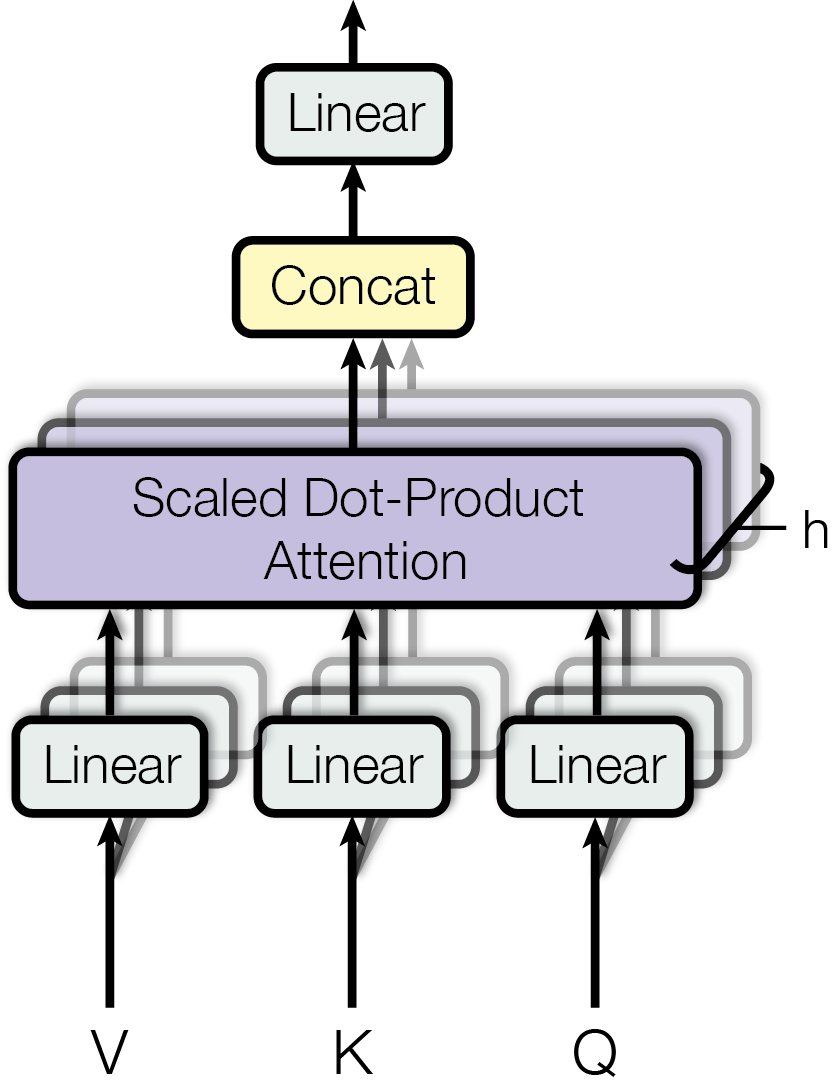
在上一节里,我们已经看到,attention 让序列中的每个位置都可以直接和其他位置建立联系。对于某个 token 来说,它不再只能依赖前一个隐藏状态,也不需要通过很多层卷积才能间接看到远处的信息,而是可以一次性根据相关性,从整个序列中聚合上下文。
如果只看这一点,attention 已经很强了。可是还有一个问题没有解决:一个 token 和其他 token 之间的关系,往往不只有一种 。
比如下面这个句子:
The animal didn’t cross the street because it was too tired.
当模型处理到 it 的时候,它可能需要关注 animal,因为这里的 it 更可能指代这个动物。但与此同时,模型也可能需要关注 tired,因为这个词决定了当前句子的因果关系;它还可能需要关注 cross 和 street,因为这些词提供了事件背景。
也就是说,同一个 token 在理解句子时,可能同时需要不同类型的信息:有的和指代有关,有的和语法结构有关,有的和语义角色有关,有的和局部搭配有关。如果我们只用一个 attention 头,那么所有这些关系都要被压缩到同一组注意力权重里。
这就是 multi-head attention 想解决的问题。它的核心思想很简单:
不要只让模型用一个视角看序列,而是让模型用多个不同的视角同时看序列。
import mathimport dnnlpyimport matplotlib.pyplot as pltimport numpy as npimport torchimport torch.nn as nnfrom torch import Tensor'figure' , dpi= 100 )'svg' )print ('PyTorch version:' , torch.__version__)
PyTorch version: 2.12.0+cpu
8.4.1 单头注意力的问题
先回忆一下单头 attention 的计算过程。给定输入序列表示:
\[
X \in \mathbb{R}^{n \times d_{\mathrm{model}}}
\]
其中 \(n\) 是序列长度,\(d_{\mathrm{model}}\) 是每个 token 的表示维度。我们会通过三个线性变换得到 query、key 和 value:
\[
Q = XW^Q, \quad K = XW^K, \quad V = XW^V
\]
然后计算 scaled dot-product attention:
\[
\operatorname{Attention}(Q, K, V)
= \operatorname{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V
\]
这套机制可以让每个位置根据 query 和 key 的匹配程度,从所有 value 中加权取回信息。
但如果只有一个 attention 头,那么模型只有一套 \(W^Q, W^K, W^V\) ,也就只有一种投影方式。换句话说,模型只能在一个表示空间里判断谁和谁相关。这并不是说单头注意力没有表达能力,而是说它的表达方式比较集中。所有关系都混在同一个注意力分布里:
当前词应该关注主语吗?
当前词应该关注宾语吗?
当前词应该关注相邻词吗?
当前词应该关注表示因果、否定、时间的信息吗?
这些不同需求都要通过同一个 attention 矩阵来表达,模型当然也可以学,但会比较受限。
一个直观的类比是:如果你读一句话,只从语义相似度这一个角度去看,确实能得到很多信息;但人类理解语言时,往往会同时看语法关系、指代关系、修饰关系、上下文逻辑等多个方面。Multi-head attention 就是在模型里提供了类似的多个观察角度。
8.4.2 多头注意力的核心思想
有了前面的直觉以后,我们就可以正式来看 multi-head attention 是怎么做的。
它并没有发明一种全新的 attention 计算方式,而是把同一种 attention 机制并行地做多次。每一次独立的 attention 计算都叫做一个 head 。也就是说,模型不再只用一套 query、key、value 去观察序列,而是同时准备多套 query、key、value,让不同 head 在不同表示空间里学习不同的匹配关系。
从整体结构上看,每个 head 都会先通过各自的线性投影得到一组 \(Q\) 、\(K\) 、\(V\) ,然后独立计算 scaled dot-product attention。多个 head 的输出会被拼接起来,最后再经过一个线性层,融合成最终的 multi-head attention 输出。
对于第 \(i\) 个 head,会有自己独立的一组线性投影矩阵:
\[
W_i^Q, \quad W_i^K, \quad W_i^V
\]
经过投影,会得到自己的一组 query、key 和 value:
\[
Q_i = XW_i^Q, \quad K_i = XW_i^K, \quad V_i = XW_i^V
\]
然后对第 \(i\) 个 head 单独计算 attention:
\[
\mathrm{head}_i
= \operatorname{Attention}(Q_i, K_i, V_i)
= \operatorname{softmax}\left(\frac{Q_i K_i^\top}{\sqrt{d_k}}\right)V_i
\]
如果一共有 \(h\) 个 head,那么我们会得到:
\[
\mathrm{head}_1, \mathrm{head}_2, \dots, \mathrm{head}_h
\]
接着,把这些 head 的输出在最后一个维度上拼接起来:
\[
\operatorname{Concat}(\mathrm{head}_1, \dots, \mathrm{head}_h)
\]
最后再经过一个线性变换 \(W^O\) ,得到最终输出:
\[
\operatorname{MultiheadAttention}(Q, K, V)
= \operatorname{Concat}(\mathrm{head}_1, \dots, \mathrm{head}_h)W^O
\]
这就是 multi-head attention 的标准形式。
需要注意的是,虽然公式里写的是 \(Q, K, V\) ,但在 self-attention 里,它们都来自同一个输入 \(X\) ;在 cross-attention 里,\(Q\) 通常来自 decoder,\(K\) 和 \(V\) 通常来自 encoder 的输出。所以,multi-head attention 并不改变 attention 的基本机制,它只是把同样的 attention 机制复制成多个 head,并让每个 head 学习不同的投影视角。
8.4.3 为什么多个头有用
Multi-head attention 最重要的作用,是让模型可以在不同子空间中并行地建模不同关系。
这里的子空间可以理解为:每个 head 都先通过自己的线性层,把原始 token 表示投影到一个新的表示空间里。由于每个 head 的投影矩阵不同,所以它们看到的不是完全一样的特征。
同一个词,在不同 head 里可能会被投影成不同的表示。某个 head 可能更容易捕捉语法关系,另一个 head 可能更容易捕捉长距离依赖,还有一个 head 可能更关注局部邻近词。当然,这些解释不是人为预先规定的,而是模型在训练过程中自己学出来的。也就是说,我们不应该把每个 head 理解成固定的人工规则,比如第一个 head 专门看主语,第二个 head 专门看宾语。每个 head 有独立的参数,因此它们有机会学习不同类型的匹配模式和信息聚合方式。
从这个角度看,multi-head attention 的价值不在于它手动规定了多个视角,而在于它给模型提供了多个可以自动学习的视角。
还是以前面的句子为例:
The animal didn’t cross the street because it was too tired.
当模型处理 it 时,不同 head 可能形成不同的关注模式。一个 head 可能把较大权重放在 animal 上,因为这有助于解决指代问题;另一个 head 可能关注 tired,因为它影响当前短语的语义解释;还有一个 head 可能关注 cross the street,因为这提供了事件背景。
最终,这些不同 head 的结果会被拼接起来,再通过输出线性层融合。这样,模型就不是从一个单一角度理解当前 token,而是把多个角度得到的信息综合起来。
不过,需要注意的是,虽然 multi-head attention 可以建模同一个序列的不同关系,但这并不意味着每个 head 都一定会学到人类理解的模式。在实际训练中,有些 head 可能确实表现出比较明确的模式,比如关注前一个 token、关注分隔符、关注句法相关词,但也有很多 head 的行为并不容易解释。
所以,在理解 multi-head attention 时,需要避免两个极端。一种极端是把它讲得太神秘,好像每个 head 都自动拥有某种高级语言学习功能。另一种极端是把它看成简单的重复计算,好像只是多算几次 attention。更合理的理解是:多头机制给模型提供了多个可学习的表示子空间,让模型能够并行捕捉不同类型的关系。
8.4.4 多头并不是简单地增加参数
那么,看到这里,一个自然的问题是:既然有多个 head,那是不是参数量和计算量都会成倍增加?
答案并不是简单的“是”。在 Transformer 里,通常会把总的模型维度 \(d_{\mathrm{model}}\) 分给多个 head。假设有 \(h\) 个 head,那么每个 head 的维度一般设为:
\[
d_k = d_v = \frac{d_{\mathrm{model}}}{h}
\]
例如,如果 \(d_{\mathrm{model}} = 512\) ,\(h = 8\) ,那么每个 head 的维度就是 \(64\) 。
这样做的结果是:每个 head 只在较低维的子空间里计算 attention。虽然 head 的数量变多了,但每个 head 的维度变小了。因此,整体计算量并不会因为 head 数量增加而简单地乘以 \(h\) 。
更具体地说,单头 attention 如果使用完整的 \(d_{\mathrm{model}}\) 维度计算,那么注意力输出维度是 \(d_{\mathrm{model}}\) 。多头 attention 则是把这个维度拆成 \(h\) 份,每个 head 计算 \(\tfrac{d_{\mathrm{model}}}{h}\) 维,最后再拼回 \(d_{\mathrm{model}}\) 。
所以,multi-head attention 更像是把一个大的注意力空间拆成多个小的注意力空间,而不是简单地复制很多个完整的大 attention。这也是为什么它可以在表达能力和计算效率之间取得一个比较好的平衡。
8.4.5 从张量形状理解多头注意力
为了更具体地理解 multi-head attention,我们可以看一下常见实现中的张量形状。
假设输入为:
\[
X \in \mathbb{R}^{B \times n \times d_{\mathrm{model}}}
\]
其中 \(B\) 是 batch size,\(n\) 是序列长度,\(d_{\mathrm{model}}\) 是模型维度。
经过线性层后,我们通常仍然先得到:
\[
Q, K, V \in \mathbb{R}^{B \times n \times d_{\mathrm{model}}}
\]
然后把最后一维拆成 head 数和每个 head 的维度:
\[
Q, K, V \in \mathbb{R}^{B \times n \times h \times d_k}
\]
为了方便并行计算,通常会把 head 维度移到前面:
\[
Q, K, V \in \mathbb{R}^{B \times h \times n \times d_k}
\]
接下来,每个 head 内部计算注意力分数:
\[
S = QK^\top \in \mathbb{R}^{B \times h \times n \times n}
\]
这里的 \(n \times n\) 就是每个 head 自己的 attention matrix。因为有 \(h\) 个 head,所以每一层 Multi-Head Attention 实际上会产生 \(h\) 张注意力矩阵。
然后经过 softmax,并乘以 \(V\) :
\[
P = \operatorname{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V
\in \mathbb{R}^{B \times h \times n \times d_k}
\]
最后,把多个 head 拼接回去:
\[
\mathbb{R}^{B \times h \times n \times d_k}
\rightarrow
\mathbb{R}^{B \times n \times d_{\mathrm{model}}}
\]
再经过输出投影 \(W^O\) ,得到最终输出。
从形状上看,multi-head attention 的本质就是:先把 \(d_{\mathrm{model}}\) 拆成多个 head,在每个 head 上独立做 attention,然后再把它们合并回来。
8.4.6 Multi-Head Attention 的 PyTorch 实现
下面我们写一个简化版本的 multi-head attention。这里先不考虑 padding mask、causal mask、dropout 等细节,只关注核心计算流程。
class MultiheadAttention(nn.Module):def __init__ (self , embed_dim: int , num_heads: int ):super ().__init__ ()if embed_dim % num_heads != 0 :raise AssertionError ('`embed_dim` must be divisible by `num_heads`.' )self .embed_dim = embed_dimself .num_heads = num_headsself .head_dim = embed_dim // num_headsself .q_proj = nn.Linear(embed_dim, embed_dim)self .k_proj = nn.Linear(embed_dim, embed_dim)self .v_proj = nn.Linear(embed_dim, embed_dim)self .out_proj = nn.Linear(embed_dim, embed_dim)def forward(self ,bool = False ,-> tuple [Tensor, Tensor | None ]:# Make sure the sequence lengths of key and value match if key.size(- 2 ) != value.size(- 2 ):raise AssertionError ('`key` and `value` must have the same sequence length.' = query.size()= key.size(- 2 )= value.size(- 2 )= self .q_proj(query)= self .k_proj(key)= self .v_proj(value)= q.view(batch_size, q_len, self .num_heads, self .head_dim)= k.view(batch_size, k_len, self .num_heads, self .head_dim)= v.view(batch_size, v_len, self .num_heads, self .head_dim)= q.transpose(1 , 2 )= k.transpose(1 , 2 )= v.transpose(1 , 2 )= q @ k.transpose(- 2 , - 1 )= scores / math.sqrt(self .head_dim)= scores.softmax(dim=- 1 )= attn_weights @ v= attn_output.transpose(1 , 2 ).contiguous()= attn_output.view(batch_size, q_len, self .embed_dim)= self .out_proj(attn_output)if need_weights:return output, attn_weightsreturn output, None
这段代码里最关键的地方是 view 和 transpose。
一开始,q、k、v 的形状都是:
(batch_size, seq_len, d_model)然后我们把 d_model 拆成:
(num_heads, head_dim)于是形状变成:
(batch_size, seq_len, num_heads, head_dim)再通过 transpose(1, 2),把 head 维度移到序列长度前面:
(batch_size, num_heads, seq_len, head_dim)这样做以后,PyTorch 就可以同时为所有 batch、所有 head 计算 attention,而不需要我们手动写循环。
最后,多个 head 的输出会再转回:
(batch_size, seq_len, num_heads, head_dim)然后重新合并成:
(batch_size, seq_len, d_model)这就是多头注意力在实现层面的核心。
我们对 multi-head attention 的注意力矩阵进行可视化:
= 2 = torch.randn(3 , 5 , 16 )# This is a version of multi-head self-attention. # You can change to cross-attention by using different `k` and `v` inputs. = MultiheadAttention(embed_dim= 16 , num_heads= num_heads)with torch.inference_mode():= multihead_attn(x, x, x, need_weights= True )print ('Input shape:' , x.shape)print ('Attention weights shape:' , attn_weights.shape)print ('Output shape:' , output.shape)= plt.figure(1 , figsize= (4 * num_heads, 3 ))= fig.subplots(1 , num_heads)for i, ax in enumerate (axes):= ax.pcolormesh(attn_weights[0 , i], cmap= 'Blues' , vmin= 0 , vmax= 0.4 )= np.arange(x.size(- 2 ))+ 0.5 , ticks)+ 0.5 , ticks)'equal' )'key/value position' )'query position' )f'Head { i + 1 } Attention Weights' )0 ].invert_yaxis()= np.arange(0 , 0.5 , 0.1 )= axes, ticks= cbar_ticks)
Input shape: torch.Size([3, 5, 16])
Attention weights shape: torch.Size([3, 2, 5, 5])
Output shape: torch.Size([3, 5, 16])
8.4.7 为什么最后还需要输出投影
在 multi-head attention 中,多个 head 的输出会被拼接起来。拼接以后,信息只是简单地放在了一起,还没有真正充分融合。因此,Transformer 会在拼接之后再接一个线性层 \(W^O\) :
\[
\operatorname{Concat}(\mathrm{head}_1, \dots, \mathrm{head}_h)W^O
\]
这个输出投影有两个作用。
第一,它把多个 head 的信息重新混合起来。不同 head 学到的是不同子空间中的信息,拼接只是把它们并排放在一起,而输出线性层可以让不同 head 之间的信息发生交互。
第二,它把输出变回模型需要的维度。通常 multi-head attention 的输入和输出都会保持 \(d_{\mathrm{model}}\) 维,这样它才能方便地和残差连接、LayerNorm、前馈网络等模块组合在一起。
也就是说,multi-head attention 并不是多个 head 各自算完就结束了。真正输出给下一层之前,还需要通过 \(W^O\) 做一次融合和整理。
8.4.8 本章小结
这一节里,我们从单头 attention 的局限出发,引出了 multi-head attention。
单头 attention 只能在一个表示空间里计算相关性,而一个 token 和上下文之间的关系往往是多方面的。Multi-head attention 通过多组独立的 \(W^Q, W^K, W^V\) ,让模型可以在多个子空间中并行地计算 attention,从而学习不同类型的匹配模式和信息聚合方式。
从实现上看,多头注意力并不是简单地复制多个完整的 attention,而是把 \(d_{\mathrm{model}}\) 拆成多个 head,每个 head 在较低维空间中计算 attention,最后再拼接并通过输出投影融合。因此,它在增强表达能力的同时,也保持了比较高的计算效率。
到这里,我们已经有了 Transformer 中最核心的模块之一:multi-head attention。下一节,我们会继续补上另一个关键问题:既然 self-attention 本身没有天然的顺序感,Transformer 是如何让模型知道 token 的位置顺序的?这就是位置编码(Positional Encoding) 。