在上一节里,我们从 Bahdanau attention 出发,看到了注意力机制最早的一个重要动机:不要把整句输入强行压缩成一个固定长度向量,而是在生成每个目标词时,动态地去源句中寻找当前最相关的信息。这个思想可以概括成一句话:
当前时刻需要什么信息,就用当前状态去输入序列里查找什么信息。
在 Bahdanau attention 中,解码器的隐藏状态会去和编码器的所有隐藏状态进行匹配,然后根据匹配程度对编码器状态做加权求和。这个过程已经非常接近现代注意力机制中的交叉注意力(Cross-Attention)。区别在于,现代 Transformer 会用更统一、更矩阵化的方式来表达这件事:一个序列提供查询,另一个序列提供可被查询的信息。
这一节我们重点讨论 cross-attention,self-attention 会放到下一节单独展开。这样,我们可以先把一个序列查询另一个序列的结构讲清楚,再过渡到一个序列查询自己的情况。
import math
import dnnlpy
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as stats
import torch
import torch.nn as nn
from torch import Tensor
plt.rc('figure', dpi=100)
dnnlpy.set_matplotlib_format('svg')
print('PyTorch version:', torch.__version__)
PyTorch version: 2.12.0+cpu
8.2.1 从软对齐到 Cross-Attention
在机器翻译任务中,我们有两个序列:
- 源语言序列,例如英文句子;
- 目标语言序列,例如中文句子。
传统 seq2seq 模型会先用编码器把源句压缩成一个上下文向量,然后解码器依赖这个向量逐步生成目标句子。Bahdanau attention 改变了这个过程:解码器不再只依赖一个固定的向量,而是在每一步生成时,都重新访问源句的所有隐藏状态。
换句话说,解码器每生成一个词,都会问一次:
对于我现在要生成的这个词,源句里哪些位置最重要?
这就是 cross-attention 的雏形。
所谓 cross-attention,就是让一个序列中的位置,去关注另一个序列中的位置。它和 self-attention 的区别在于,self-attention 是一个序列内部互相看,而 cross-attention 是两个序列之间发生交互。
如果用机器翻译来理解:
- 目标序列中的某个位置负责提出问题;
- 源序列中的每个位置负责提供候选信息;
- 模型根据相关性,从源序列中取回对当前生成最有用的内容。
所以,cross-attention 本质上就是一种跨序列的信息检索机制。
8.2.2 Query、Key、Value:动态信息检索的三要素
现代 attention 通常会用 query、key、value 来描述这个过程。虽然这三个名字看起来有些抽象,但它们背后的直觉并不复杂。我们可以把 attention 想象成一次检索:
- Query 表示当前我们想找什么;
- Key 表示每个位置如何参与匹配;
- Value 表示每个位置真正提供什么内容。
从直觉上看,这很像我们平常上网搜索资料。我们在输入框里输入自己想找的内容,搜索引擎会返回一组候选结果。每条结果通常都有一个标题,以及对应的网页内容。我们会先根据自己当前的需求和这些标题,判断哪些结果更值得关注,然后再从这些结果的具体内容里提取真正有用的信息。
在 cross-attention 中,query 和 key、value 通常来自不同序列。例如,在机器翻译里,编码器输出的隐藏状态就是 key 和 value,而解码器当前的隐藏状态就是 query。解码器用 query 去匹配编码器的 key,得到一组权重,然后对编码器的 value 做加权求和,得到当前目标位置需要的上下文信息。
这其实就是 Bahdanau attention 的核心思想,只不过现代 attention 把当前解码器状态和所有编码器状态的匹配过程,统一写成了 Q、K、V 的形式,同时把 K 和 V 拆开,增强模型的表达能力。
因此,在 cross-attention 里,一个很自然的对应关系是:
- Query 来自正在生成或正在更新的序列;
- Key 和 value 来自被查询的序列。
也就是说,谁在提问,谁就产生 query;谁被查询,谁就产生 key 和 value。
这句话很重要。Cross-attention 并不是要求两个序列必须同等地互相看,而是有一个明确的方向:一个序列主动查询,另一个序列提供可被查询的信息。
到这里,我们已经大体熟悉了 query、key 和 value。但是,相信大家还有很多疑问:为什么要把这些角色拆开?尤其是为什么来自同一个被查询序列的 key 和 value 还要分开?我们在下一小节里来详细讨论这个问题。
8.2.3 为什么要拆成 Query、Key、Value?
上一小节里,我们把 Q、K、V 看成 attention 中的三种角色:query 表示当前需求,key 用来参与匹配,value 用来提供内容。这个说法很方便理解,但它也会带来几个自然的问题:
- 为什么要把输入拆成 query、key、value?
- 既然在 cross-attention 中 key 和 value 通常来自同一个序列,为什么 key 和 value 还要分开?
- 我能不能自己再加一个,比如 Q、K、V、W?
我们先看第一个问题:为什么需要 Q、K、V。
这个问题比较好解释。实际上,如果不拆成 Q、K、V,那么同一个向量就又要同时承担我想找什么、我是否值得被匹配、如果被关注应该提供什么内容这几个角色。这就又回到了我们之前那个固定上下文向量的问题:它需要同时承担多个不同的功能,模型表达能力会受限。而拆成 Q、K、V 后,模型就可以从不同角度,分别学习出查询需求、匹配特征、可传递内容,从而自己学会如何组织信息。
接下来再看第二个问题:为什么 key 和 value 要分开。
一个直观的回答是:用于匹配的信息和最终取回的信息可以不是同一种信息。
在搜索引擎里,我们可能先看标题、关键词或摘要来判断一个网页是否相关;但真正需要的信息,可能藏在网页正文里。标题适合匹配,正文适合提供内容。两者相关,但并不完全相同。
Attention 里一个很重要的设计,就是把两件事分开了:
- 第一件事:谁和我现在最相关?
- 第二件事:如果我关注它,它能提供什么信息?
这就好比我们在图书馆找书。我们心里有一个需求,这有点像 query;我们会通过书名、目录、标签或摘要判断哪本书相关,这些线索有点像 key;而真正被我们阅读和吸收的,是书里的具体内容,这有点像 value。
如果 key 和 value 完全绑死,模型只能用同一种表示同时做匹配和内容传递;如果 key 和 value 分开,模型就可以用一种表示决定谁更相关,再用另一种表示决定相关位置应该贡献什么。也就是说:
- 如果我们改变 key,会改变模型关注源序列的哪些位置;
- 如果我们改变 value,在注意力权重不变的情况下,会改变模型取回的内容。
所以,attention 的注意力权重由 query 和 key 决定,但最终输出还取决于 value。把 key 和 value 分开以后,模型就可以把匹配空间和内容空间解耦开来,让它们分别学习不同的功能。
对于第三个问题:我能不能自己再加一个,比如 Q、K、V、W?
从理论上讲,当然可以。我们完全可以设计一个更复杂的 attention 机制,增加更多的角色,比如 W 代表某种辅助信息,或者引入更多的匹配维度。但是,Q、K、V 已经被证明是非常有效的设计。它们把 attention 的核心功能分成了三个角色,既有足够的表达能力,又不会过于复杂。增加更多角色可能会让模型更难训练,或者需要更多的数据来学习这些角色的分工。
不过,需要注意的是,attention 里很多具体设计,并不是从某个理论中必然推出来的。我们现在所作的解释是一种事后解释。更准确地说,它们是一组在实践中被证明有效、便于训练和实现的设计选择。也正因为如此,关于为什么不是 Q、K、V、W,打分函数能不能用其他相似度,往往并不存在标准答案。不同设计通常是在表达能力、计算效率、训练稳定性和实现复杂度之间做权衡。这也是为什么 attention 有很多变体的原因。
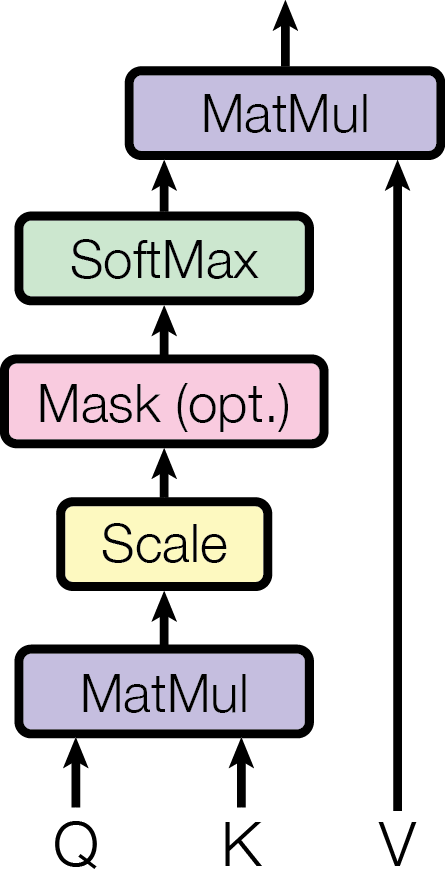
8.2.5 Cross-Attention 的矩阵形式
现在我们用矩阵形式写出 cross-attention。
假设有两个序列:
- 查询序列表示为 \(X \in \mathbb{R}^{n_x \times d}\);
- 被查询序列表示为 \(Y \in \mathbb{R}^{n_y \times d}\)。
其中,\(n_x\) 是查询序列的长度,\(n_y\) 是被查询序列的长度,\(d\) 是隐藏维度。
Cross-attention 首先通过线性投影得到:
\[
Q = X W_Q, \quad K = Y W_K, \quad V = Y W_V
\]
然后计算 query 和 key 之间的相似度:
\[
S = QK^\top
\]
这里的 \(S \in \mathbb{R}^{n_x \times n_y}\)。它的第 \(i\) 行、第 \(j\) 列表示查询序列中的第 \(i\) 个位置对被查询序列中第 \(j\) 个位置的相关性分数。
接着,对每一行做 softmax,把分数变成权重:
\[
P = \operatorname{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)
\]
最后,用这些权重对 value 做加权求和:
\[
O = PV
\]
合在一起,就是我们非常熟悉的 scaled dot-product attention:
\[
\operatorname{Attention}(Q, K, V) = \operatorname{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V
\]
在 cross-attention 中,最关键的一点是 Q 来自一个序列,而 K 和 V 来自另一个序列。这也是它被称为 cross-attention 的原因。它广泛适用于机器翻译、图文匹配、问答等需要跨序列交互的任务。
下面这段代码,我们用随机张量实现一个最小版的 cross-attention。这里 x 和 y 是两个不同序列,Q 来自 x,K 和 V 来自 y。
这里需要说明的是,我们的实现主要是对齐 PyTorch 的 nn.MultiheadAttention,而不是实现 attention 在维度设计上的最一般形式。
在 nn.MultiheadAttention 中,embed_dim 同时表示 query 的输入维度、query/key/value 投影后的总维度,以及最终 attention 输出的维度。它只额外提供 kdim 和 vdim,用来允许 key/value 的原始输入维度与 query 不同。
不过从 attention 机制本身来看,维度可以更灵活。query、key、value 的输入维度可以不同,query/key 的匹配维度和 value 的内容维度也可以不同,最终输出维度也不一定要等于 embed_dim。只要 query 和 key 能正确计算 attention score,并且 attention weight 能和 value 对齐做加权求和,这个 attention 计算就是成立的。
class CrossAttention(nn.Module):
def __init__(self, embed_dim: int):
super().__init__()
self.embed_dim = embed_dim
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
self.out_proj = nn.Linear(embed_dim, embed_dim)
def forward(
self,
query: Tensor,
key: Tensor,
value: Tensor,
need_weights: bool = False,
) -> tuple[Tensor, Tensor | None]:
# Make sure the sequence lengths of key and value match
if key.size(-2) != value.size(-2):
raise AssertionError(
'`key` and `value` must have the same sequence length.'
)
q = self.q_proj(query)
k = self.k_proj(key)
v = self.v_proj(value)
scores = q @ k.transpose(-2, -1)
scores = scores / math.sqrt(self.embed_dim)
attn_weights = scores.softmax(dim=-1)
attn_output = attn_weights @ v
output = self.out_proj(attn_output)
if need_weights:
return output, attn_weights
return output, None
我们来测试一下这个 cross-attention 的输入输出形状:
x = torch.randn(3, 5, 16) # query sequence, length = 5
y = torch.randn(3, 8, 16) # key/value sequence, length = 8
cross_attn = CrossAttention(embed_dim=16)
with torch.inference_mode():
Q = cross_attn.q_proj(x)
K = cross_attn.k_proj(y)
V = cross_attn.v_proj(y)
output, attn_weights = cross_attn(x, y, y, need_weights=True)
print('Q shape:', Q.shape)
print('K shape:', K.shape)
print('V shape:', V.shape)
print('Attention weights shape:', attn_weights.shape)
print('Output shape:', output.shape)
Q shape: torch.Size([3, 5, 16])
K shape: torch.Size([3, 8, 16])
V shape: torch.Size([3, 8, 16])
Attention weights shape: torch.Size([3, 5, 8])
Output shape: torch.Size([3, 5, 16])
可以看到,attention weights 的形状是 (batch size, query length, key/value length)。也就是说,查询序列中的每个位置,都会对被查询序列中的所有位置分配一组权重。
我们把这个权重矩阵可视化一下。
fig = plt.figure(1, figsize=(5, 3))
ax = fig.add_subplot(1, 1, 1)
im = ax.pcolormesh(attn_weights[0], cmap='Blues', vmin=0, vmax=0.4)
x_ticks = np.arange(y.size(-2))
y_ticks = np.arange(x.size(-2))
cbar_ticks = np.arange(0, 0.5, 0.1)
ax.set_xticks(x_ticks + 0.5, x_ticks)
ax.set_yticks(y_ticks + 0.5, y_ticks)
ax.invert_yaxis()
ax.set_xlabel('key/value position')
ax.set_ylabel('query position')
ax.set_title('Cross-Attention Weights')
ax.set_aspect('equal')
fig.colorbar(im, shrink=0.85, ticks=cbar_ticks)
plt.show()
图中的第 \(i\) 行第 \(j\) 列表示查询序列的第 \(i\) 个位置对被查询序列的第 \(j\) 个位置的关注程度。颜色越深表示权重越大,也就是查询位置越关注被查询位置的信息。由于这是 cross-attention,横轴和纵轴对应的是两个不同序列。
不过,这里还有一个看起来很小但其实很关键的细节:我们在计算 scores 时,并不是直接写 Q @ K.T,而是把点积的结果除以了 \(\sqrt{d_k}\)。这个细节虽然看起来不起眼,但它对模型的训练稳定性有着非常重要的影响。那么,这是为什么呢?
8.2.6 为什么要除以 \(\sqrt{d_k}\)?
在 Transformer 里,最常见的形式就是我们刚刚讲的 scaled dot-product attention:
\[
\operatorname{Attention}(Q, K, V) = \operatorname{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V
\]
它和最原始的 attention 的差异,就是把分数除以 \(\sqrt{d_k}\)。
为什么要这样做?因为当特征维度 \(d_k\) 变大时,点积的数值往往也会变大。如果直接把这些较大的分数送进 softmax,那么 softmax 很容易变得特别尖锐,也就是某一个位置的概率接近 1,其他位置几乎接近 0。这样一来,梯度就可能变小,训练也会变得不稳定。所以,除以 \(\sqrt{d_k}\) 本质上是在控制分数的尺度,让 softmax 保持在一个更合适的工作区间。
我们可以用下面的代码直观看一下这个现象。我们随机生成 query 和 key,在不同维度下比较缩放前后的注意力分布熵。熵越低,说明分布越尖锐。
def average_entropy(
d_k: int, num_queries: int = 2048, num_keys: int = 10
) -> tuple[float, float]:
q = torch.randn(num_queries, d_k)
k = torch.randn(num_keys, d_k)
raw_scores = q @ k.T
scaled_scores = raw_scores / math.sqrt(d_k)
raw_prob = raw_scores.softmax(dim=-1)
scaled_prob = scaled_scores.softmax(dim=-1)
raw_entropy = stats.entropy(raw_prob, axis=-1).mean()
scaled_entropy = stats.entropy(scaled_prob, axis=-1).mean()
return raw_entropy, scaled_entropy
dims = [8, 32, 128, 512]
raw_entropies = []
scaled_entropies = []
for d in dims:
raw_h, scaled_h = average_entropy(d)
raw_entropies.append(raw_h)
scaled_entropies.append(scaled_h)
fig = plt.figure(2, figsize=(5, 3))
ax = fig.add_subplot(1, 1, 1)
ax.plot(dims, raw_entropies, marker='o')
ax.plot(dims, scaled_entropies, marker='o')
ax.set_xscale('log', base=2)
ax.set_yticks(np.arange(0, 2.25, 0.25))
ax.set_xlabel('$d_k$')
ax.set_ylabel('Average Entropy')
ax.legend(['Unscaled', r'Scaled by $\sqrt{d_k}$'], loc='center right')
ax.set_title('Scaling Effect on Softmax Sharpness')
plt.show()
你看,不缩放时,随着 \(d_k\) 的增大,softmax 会越来越尖锐,熵下降得更明显;而做了缩放之后,分布会稳定很多。这就是 scaled dot-product attention 成为标准配置的重要原因。
8.2.7 一个目标位置如何查询整个源序列
为了更具体地理解 cross-attention,我们只看目标序列中的一个位置。
假设解码器现在要生成目标句子中的第 \(i\) 个词。此时它有一个隐藏表示 \(x_i\),这个表示会被投影成 query:
\[
q_i = x_i W_Q
\]
源句中每个位置的编码器输出会被投影成 key 和 value:
\[
k_j = h_j W_K, \quad v_j = h_j W_V
\]
其中,\(h_j\) 是源句第 \(j\) 个位置的编码器表示。
然后,当前 query 会和所有 key 计算相关性:
\[
s_{ij} = q_i \cdot k_j
\]
这些分数经过 softmax 后得到注意力权重:
\[
\alpha_{ij} = \frac{\exp(s_{ij})}{\sum_l \exp(s_{il})}
\]
最后,模型对所有 value 做加权求和:
\[
o_i = \sum_j \alpha_{ij} v_j
\]
这个输出 \(o_i\) 就是目标位置 \(i\) 从源序列中取回来的上下文信息。
从这个角度看,cross-attention 并不是把源句压缩成一个向量,而是为目标序列中的每个位置都生成一个动态上下文。不同目标位置可以关注源句的不同部分,因此它天然适合建模翻译、图文匹配、问答等需要跨序列交互的任务。
8.2.9 本章小结
这一节里,我们从 Bahdanau attention 的软对齐思想过渡到了现代 cross-attention。
从思想上看,cross-attention 延续了 Bahdanau attention 的关键动机:不要把所有输入信息压缩成一个固定向量,而是让模型在需要时动态访问相关信息。从实现上看,现代 Transformer 用 Q、K、V 和矩阵乘法,把这种动态访问写成了统一、高效、可并行的计算模块。
同时,我们也要记住,Q、K、V 不是从某个完美理论中唯一推导出来的结构,而是一种非常成功的工程设计。它把“提出查询”“参与匹配”“提供内容”分成了几个可学习的角色,让模型能够在训练中自己学会如何组织信息。理解这层分工就足够了,不需要把每一个设计都解释成某种必然。
不过,到目前为止,我们讨论的仍然是两个序列之间的交互。接下来,一个更自然的问题是:如果没有另一个序列,只有一个序列本身,它能不能也用同样的方式让内部不同位置互相查询?
这就是下一节要讲的内容:自注意力(Self-Attention)。